3.2. Матричное описание линейных блоковых кодов
Линейный код Ψ образует подпространство в GF n (q). Любое множество базисных векторов может быть использовано в качестве строк для построения (k × n) – матрицы G, которая называется порождающей матрицей кода. Пространство строк матрицы G есть линейный код Ψ , любое кодовое слово есть линейная комбинация строк из G. Множество qk кодовых слов называется линейным (n, k) – кодом. Строки матрицы G линейно независимы, и число строк k равно размерности подпространства. Размерность всего пространства GF n (q) равна n. Всего существует qk кодовых слов, и qk различных k – последовательностей над GF (q) могут быть отображены на множество кодовых слов.
Любое взаимно однозначное соответствие k – последовательностей и кодовых слов может быть использована для кодирования, но наиболее естественный способ кодирования использует отображение
c = i ∙ G, (3.2)
где i – информационное слово, представляющее собой k – последовательность кодируемых информационных символов, а c – образующая кодовое слово n – последовательность. Задаваемое последним равенством соответствие между информационным и кодовым словами определяет кодер и зависит от выбора базисных векторов в качестве строк матрицы G; в то же время само множество кодовых слов не зависит от этого выбора.
Поскольку Ψ является подпространством, оно имеет ортогональное дополнение Ψ┴ которое состоит из всех векторов, ортогональных к Ψ. Ортогональное дополнение также является подпространством и, таким образом, может рассматриваться как код. Когда Ψ┴ само рассматривается как код, оно называется кодом дуальным к Ψ.
Ортогональное дополнение Ψ┴ имеет размерность n – k, и любой его базис также состоит из n – k векторов. Пусть Н – матрица со строками, являющимися этими базисными векторами. Тогда n – последовательность с является кодовым словом в том и только том случае, когда она ортогональна каждой вектор-строке матрицы H, то есть когда
сH т = 0. (3.3)
Это равенство позволяет проверить, является ли данное слово кодовым. Матрица H называется проверочной матрицей кода. Она является (n — k) × n матрицей; поскольку это равенство выполняется при подстановке вместо с любой строки матрицы G, то
GH т = 0. (3.4)
Из (n, k) – кода с минимальным расстоянием d* можно получить новый код с теми же параметрами, если в каждом кодовом слове выбрать две позиции и поменять местами символы в этих позициях. Однако в этом случае мы получим код эквивалентный исходному. Порождающие матрицы G и G’ эквивалентных кодов просто связаны друг с другом. Сам код является пространством строк матрицы G и поэтому остается неизменным при элементарных операциях над строками. Перестановка координат кода эквивалентна перестановке столбцов в матрице G.
Каждая порождающая матрица G эквивалентна некоторой матрице канонического ступенчатого вида. Следовательно, с точностью до перестановки столбцов любая порождающая матрица эквивалентна матрице, которая в первых k столбцах содержит единичную подматрицу размером k ´ k.. Эквивалентную матрицу можно записать в виде :
G = [ I : P ], (3.5)
где P – есть k ´ (n — k) – матрица. Такую порождающую матрицу будем называть порождающей матрицей в систематическом виде. Следовательно определением проверочной матрицы в систематическом виде является равенство :
H = [ -P т : I ]. (3.6)
Следовательно систематическим кодом называется код, у которого каждое кодовое слово начинается с информационных символов, оставшиеся символы называются проверочными символами.
Систематический линейный код кодируется умножением информационного вектора на порождающую матрицу G в систематическом виде. В качестве примера выберем:
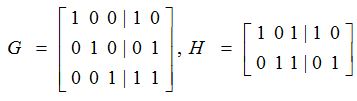
тогда i = [ 0 1 1 ] при систематическом кодирование отобразится в слово с = [ 0 1 1 1 0 ].
Рассматривая код в систематическом виде, можно получить простое неравенство, связывающее параметры кода. Эта граница является очень неточной, и большинство хороших кодов имеет минимальное расстояние, существенно меньше, чем следует из границы. Пусть задан некоторый систематический (n, k) – линейный код с минимальным расстоянием d*. Тогда минимальное расстояние (минимальный вес) любого линейного (n, k) –кода (граница Синглтона) удовлетворяет неравенству :
d* £ 1 + n – k . (3.7)
3.3. Совершенные и квазисовершенные коды
Рассмотрим маленькие сферы с центрами во всех кодовых словах; все эти сферы имеют один и тот же (целочисленный) радиус. Пусть теперь радиус сфер увеличивается (оставаясь целыми числами) до тех пор, пока дальнейшее увеличение радиуса будет невозможно без пересечения сфер. Значение этого радиуса равно числу исправляемых кодом ошибок. Этот радиус называется радиусом сферической упаковки кода. Теперь будем увеличивать радиус до тех пор, пока каждая точка пространства не окажется внутри хотя бы одной сферы. Такой радиус называется радиусом покрытия кода.
Совершенный код есть код, для которого сферы некоторого одинакового радиуса вокруг кодовых слов, не пересекаясь, покрывают все пространство.
Квазисовершенный код – это код , у которого сферы радиуса t вокруг каждого кодового слова не пересекаются и все слова, не лежащие внутри какой-либо из этих сфер, находятся на расстоянии t + 1 хотя бы от одного кодового слова.
3.4. Циклические коды
Циклические коды над GF(q) представляют собой подкласс в классе линейных кодов. Линейный код называется циклическим, если из того, что слово с = (с0, с1,…, сn-1) принадлежит Ψ, следует, что слово с’= (cn-1, с0,…, сn-2) так же принадлежит Ψ. Кодовое слово с’ получается из кодового слова с циклическим сдвигом всех компонент на одну позицию вправо. Каждый линейный код над GF(q) длины n представляет собой подпространство пространства GF n (q), а циклический код является частным случаем подпространства, так как обладает дополнительным свойством цикличности.
Каждый вектор из GF n (q) можно представить многочленом от х степени не выше n – 1. Компоненты вектора отождествляются с коэффициентами многочлена. Множество многочленов обладает структурой векторного пространства, идентичной структуре пространства GF n (q). Это же множество многочленов обладает структурой кольца GF(q) [x] / (x n – 1), в котором определено умножение :
p1(x) p2(x) = R x n— 1[ p1(x) p2(x) ], (3.8)
где правая часть равенства обозначает остаток от деления произведения p1(x) p2(x) на двучлен x n – 1.
Циклический сдвиг может быть записан через умножение :
x∙p (x) = R x n— 1[ x∙p (x) ]. (3.9)
Итак, если кодовые слова некоторого кода задаются в виде многочленов, то код является подмножеством кольца GF(q) [x] / (x n – 1). Такой код является циклическим, если вместе с каждым кодовым словом с(х) он содержит кодовый многочлен х∙с(х).
Единственный приведенный ненулевой многочлен наименьшей степени равной n – k в коде Ψ называется порождающим многочленом кода Ψ и обозначается через g (x). Циклический код состоит из всех произведений порождающего многочлена g (x) на многочлены степени не выше k – 1.
Циклический код длины n с порождающим многочленом g (x) существует тогда и только тогда, когда g (x) делит x n – 1. следовательно для порождающего многочлена g (x) любого циклического кода выполняется равенство :
x n – 1 = g (x) ∙ h (x) (3.10)
при некотором многочлене h (x). Многочлен h (x) называется проверочным многочленом. Каждое кодовое слово с (х) удовлетворяет равенству :
R x n— 1[ h (x) ∙ c (x) ] = 0 , (3.11)
так как h (x) ∙ c (x) = h (x) ∙ g (x) ∙ a (x) = (x n – 1) ∙ a (x) для некоторого многочлен a (x).
Пусть c (x) обозначает переданное кодовое слово. Это значит, что символами переданного слова были коэффициенты многочлена с (x) . Пусть многочлен v (x) обозначает принятое слово, и пусть e (x) = v (x) – c (x). Многочлен e (x) называется многочленом ошибок. Ненулевые коэффициенты этого многочлена стоят в тех позициях, где в канале произошли ошибки.
Информационную последовательность в виде многочлена i (x) степени k – 1 можно отобразить в кодовый многочлен простым правилом кодирования :
c (x) = i (x) ∙ g (x). (3.12)
Такой кодер является не систематическим, так как по многочлену c (x) нельзя сразу установить i (x). Систематическое правило кодирования имеет более сложный вид. Идея состоит в записи информации в виде старших коэффициентов кодового многочлена и подборе младших коэффициентов так, чтобы получить допустимое кодовое слово. То есть кодовое слово записывается в виде :
c (x) = x n – k ∙i (x) + t (x), (3.13)
где t (x) выбирается так, чтобы выполнялось условие :
R g (x) [c (x)] = 0. (3.14)
Это требование означает, что
R g (x) [x n – k ∙i (x)] + R g (x) [t (x)] = 0 (3.15)
и степень многочлена t (x) меньше n – k, степени многочлена g (x). Следовательно
t (x) = – R g (x) [x n – k ∙i (x)], (3.16)
и правило кодирование является взаимно-однозначным, так как k старших коэффициентов многочлена определены однозначно.
Определим синдромный многочлен s (x), который будет использован для декодирования, как остаток от деления v (x) на g (x) :
s (x) = R g (x) [v (x)] = R g (x) [c (x) + e (x)] = R g (x) [e (x)]. (3.17)
Синдромный многочлен зависит только от e (x) и не зависит ни от c (x), ни от i (x).
Итак, были введены следующие многочлены :
порождающий многочлен g (x), deg g (x) = n – k,
проверочный многочлен h (x), deg h (x) = k,
информационный многочлен i (x), deg i (x) = k – 1,
кодовый многочлен c (x), deg c (x) = n – 1,
многочлен ошибок e (x), deg e (x) = n – 1,
принятый многочлен v (x), deg v (x) = n – 1,
синдромный многочлен s (x), deg s (x) = n – k – 1.
Пусть d* — минимальное расстояние циклического кода Ψ. Каждому многочлену ошибок веса меньше, чем d*/2, соответствует единственный синдромный многочлен. Таким образом, задача исправления ошибок сводится к однозначному вычислению многочлена e (x) с наименьшим числом ненулевых коэффициентов, удовлетворяющего условию :
s (x) = R g (x) [e (x)]. (3.18)
При не очень большом числе входов эта задача может быть решена путем построения таблиц так, как это показано в таблице 3.1.
Таблица 3.1. Таблица значений синдромов.
| e (x) | s (x) |
| 1 x x2 … 1 + x 1 + x2 … | R g (x) [1] R g (x) [x] R g (x) [x2] … R g (x) [1 + x] R g (x) [1 + x2] … |
Для каждого корректируемого многочлена e (x) вычисляется и табулируется многочлен s (x). Вычисляя s (x) по принятому v (x), декодер находит s (x) в таблице значений синдромов, а затем соответствующий многочлен e (x).
ГЛАВА 4. СТРУКТУРА КОДА ГОЛЕЯ
4.1. Двоичный код Голея
Самые известные и, возможно, самые полезные из линейных блочных кодов – коды Голея (23, 12) и (24, 12) с минимальными расстояниями равными соответственно 7 и 8. Первый из них называют совершенным кодом. Это означает, что все сферы радиуса r = 3 вокруг кодовых слов (то есть множества всех слов на расстоянии Хэмминга r от кодовых слов) не пересекаются и что каждый из слов находится на расстоянии, не превышающем r, хотя бы от одного из кодовых слов. Код Голея (24 , 12) – единственный квазисовершенный код. Это означает, что все сферы радиуса r = 3 вокруг кодовых слов не пересекаются, но каждый из слов находится на расстоянии, не превышающем r + 1, хотя бы от одного кодового слова .
Коды Голея входят в немногочисленный класс линейных кодов, для которых известны веса всех кодовых слов. Веса кодовых слов расширенного (24, 12) – кода легко получить, так как вес любого кодового слова (23, 12) – кода, имеющего нечетный вес, увеличивается на 1. Эти веса перечислены в таблице 4.1.
Таблица 4.1. Веса кодовых слов кодов Голея
| Вес , W | Число кодовых слов веса w | |
| Код (23, 12) | Код (24, 12) | |
| 0 7 8 11 12 15 16 23 24 | 1 253 506 1288 1288 506 253 1 0 | 1 0 759 0 2576 0 759 0 1 |
| Общее число | 4096 | 4096 |
Совершенный код Голея (23, 12) в силу своей структуры исправляет все векторы ошибок веса 3 или меньшего и только их, а ошибки веса большего или равного 4 не исправляются никогда. Квазисовершенный код Голея (24, 12) так же исправляет все векторы ошибок веса 3 или меньшего, но в отличие от совершенного кода, в силу своего свойства квазисовершенности, он дает возможность исправлять ошибки веса 4. Ошибки веса большего или равного 5 не исправляются никогда. Вследствие чего в дипломной работе используется код Голея (24, 12) , а ошибки веса 4 исправляются с помощью перебора кодовых слов находящихся на расстоянии Хэмминга равным 4 от ошибочного кодового слова.
Рассмотрим код Голея (23, 12), так как код Голея (24, 12) получается из (23, 12) – кода путем добавления двенадцатого проверочного символа, который равен 1, если вес кодового слова (23, 12) – кода нечетный, иначе этот символ равен 0.
В качестве порождающего многочлена (23, 12) – кода Голея как двоичного циклического кода можно использовать один из двух следующих многочленов:
g (x) = x11 + x10 + x6 + x5 + x4 + x2 + 1
g’ (x) = x11 + x9 + x7 + x6 + x5 + x + 1.
В дипломной работе используется порождающий многочлен g (x) степени 11. Кодирование информационного многочлена i (x) степени 11 происходит по систематическому правилу кодирования, то есть кодовый многочлен c (x) степени 22 записывается в виде:
c (x) = x 11 ∙i (x) + t (x),
где t (x) многочлен равный
t (x) = R g (x) [x 11 ∙i (x)],
и степень многочлена t (x) меньше 11, степени многочлена g (x). Следовательно старшие 12 бит кодового слова содержат информационные символы, а остальные 11 бит содержат проверочные символы.
Декодирование принятого кодового слова происходит с помощью декодера Меггитта для кода Голея, описанного ниже.
4.2. Методы декодирования циклических кодов
Наиболее сложной частью декодера является табулирование заранее вычисленных синдромных многочленов и соответствующих им многочленов ошибок. Такой табличный декодер можно значительно упростить, воспользовавшись сильной алгебраической структурой кода для отыскания связей между синдромами. Опираясь на эти связи, можно запомнить только многочлены ошибок, соответствующие некоторым типичным синдромным многочленам. Вычисление остальных необходимых величин осуществляется затем с помощью простых вычислительных алгоритмов.
Простейший декодер такого типа, так называемый декодер Меггитта, проверяет синдромы только для тех конфигураций ошибок, которые расположены в старших позициях. Декодирование ошибок в остальных позициях основано на циклической структуре кода и осуществляется позже. Соответственно таблица синдромов содержит только те синдромы, которые соответствуют многочленам ошибок с ненулевым коэффициентом e n — 1. Если вычисленный синдром находится в этой таблице, то e n — 1 исправляется. Затем принятое слово циклически сдвигается и повторяется процесс нахождения возможной ошибки в предшествующей по старшинству позиции (e n — 1 ≠ 0). Этот процесс повторяется последовательно для каждой компоненты; каждая компонента проверяется на наличие ошибки, и если ошибка найдена, то она исправляется.
В действительности нет необходимости вычислять синдромы для всех циклических сдвигов принятого слова. Новый синдром можно легко вычислить по уже вычисленному. Основная взаимосвязь описывается следующим утверждением :
так как
g (x) ∙ h (x) = x n – 1 и R g (x) [v (x) ] = s (x),
то
R g (x) [ x ∙ v (x) (mod x n — 1) ] = R g (x) [ x ∙ s (x) ] .
Из этого утверждения следует, что многочлены ошибок и соответствующие им синдромные многочлены удовлетворяют равенству
R g (x) [ x ∙ e (x) (mod x n — 1) ] = R g (x) [ x ∙ s (x) ] .
Если e (x) – исправляемая конфигурация ошибок, то многочлен
e’ (x) = x ∙ e (x) (mod x n — 1)
получается циклическим сдвигом многочлена e (x). Следовательно, e’ (x) также является исправляемой конфигурацией ошибки, и его синдром дается равенством
s’ (x) = R g (x) [e’ (x) ] = R g (x) [ x ∙ s (x) ].
Это соотношение показывает, как вычислять синдром произвольного циклического сдвига конфигурации ошибки, синдром которой известен.
Допустим, что s (x) и e (x) представляют собой вычисленные синдром и ошибку соответственно и пусть надо проверить, является ли s’ (x) синдромом для многочлена ошибок e’ (x). Сначала нужно проверить, выполняется ли равенство s (x) = s’ (x) ; если да, то e (x) = e’ (x). Если нет, то нужно вычислить R g (x) [ x ∙ s (x) ] и сравнить его с s’ (x). Если они совпадают, то
e’ (x) = x ∙ e (x) (mod x n — 1)
представляет собой циклический сдвиг многочлена e (x). Продолжая таким образом, вычислим R g (x) [ x ∙ R g (x) [ x ∙ s (x) ] ] и в случае совпадения этого многочлена с s’ (x) конфигурация ошибки e’ (x) равна x2 ∙ e (x) (mod x n — 1), и так далее.
Таблицы из таких конфигураций ошибок составляются так, чтобы каждая исправляемая конфигурация была циклическим сдвигом одной (или нескольких) из них. Тогда в декодере необходимо запомнить только эту таблицу и таблицу соответствующих синдромных многочленов с ненулевыми старшими компонентами. Истинный синдром s (x) сравнивается со всеми синдромами, которые содержатся в таблице. Затем вычисляется R g (x) [ x ∙ s (x) ] и тоже сравнивается со всеми содержащимися в таблице синдромами. Повторяя этот процесс n раз, находим любую исправляемую кодом ошибку.
Декодирование принятого слова представленный многочленом v (x) начинается с вычисления синдрома s (x) = R g (x) [v (x) ]. Далее вычисленный синдром сравнивается со всеми табличными синдромами, и в случае совпадения старший разряд принятого слова исправляется. После этого синдром и принятое кодовое слово один раз циклически сдвигаются влево. Это реализует умножение синдрома на x и деление результата на g (x). Теперь синдром равен многочлену R g (x) [ x ∙ s (x) ], представляющему собой синдром ошибки x∙e (x)(mod x n -1). Если этот новый синдром совпадает с одним из табличных синдромов, то в предыдущей по старшинству позиции произошла ошибка Этот бит исправляется, и производится новый циклический сдвиг на одну позицию. После повторения этого процесса n раз все биты будут исправлены.
Обычно декодер Меггитта используют в несколько иной форме, отличающейся от предыдущей использованием модификацией синдрома.
Чтобы понять использование модификации синдрома, предположим, что при наличии ошибки ее нужно исправить и полностью ликвидировать ее влияние так, как будто ее не было вообще. Согласно теореме Меггитта необходимо позаботиться только о случае, когда ошибка произошла в старшем символе. После этого остальные компоненты будут учтены автоматически.
Пусть e’ (x) = e n — 1x n — 1. Тогда вклад в синдром от этой единственной компоненты вектора ошибок равен
s’ (x) = R g (x) [e n — 1 ∙ x n — 1].
После исправления e n — 1 этот вклад надо вычесть из истинного синдрома, заменив содержимое s (x) синдромного регистра на s (x) – s’ (x). Но многочлен s’ (x) может иметь много ненулевых коэффициентов, так что такое вычитание затрагивает многие коэффициенты синдрома и создает дополнительные неудобства. Чтобы избежать этих неудобств, изменим определение синдрома, задав его равенством
s (x) = R g (x) [x n — k ∙ v (x)].
Это определение отличается от первоначального, но с ним можно работать точно также, как и с первоначальным. Его преимущество состоит в том, что
s’ (x) = R g (x) [x n — k ∙ e n — 1 ∙ x n — 1] = R g (x) [ R x n — 1 [e n — 1 ∙ x 2 n – k – 1] ] = R g (x) [e n — 1 ∙ x n – k – 1] = e n — 1 ∙ x n – k – 1,
так как степень многочлена g (x) равна n – k. Но теперь отличен от нуля только один коэффициент многочлена s’ (x), а именно старший. Соответственно после исправления e n — 1 для замены s (x) на s (x) – s’ (x) достаточно только вычесть e n – 1 из старшего коэффициента синдрома. При этом полностью ликвидируется вклад, вносимый в синдром исправляемым символом.
4.3. Декодер Меггитта для кода Голея
Опишем декодер Меггитта для (23, 12) — кода Голея, который используется в дипломной работе. Длина вектора ошибок равна 23, а вес не превосходит 3. Длина синдромного вектора равна 11. Если данная конфигурация ошибок не вылавливается, то она не может быть циклически сдвинута так, чтобы все три ошибки появились в 11 младших разрядах. Можно убедиться, что в этом случае по одну сторону от одной из трех ошибочных позиций стоит по меньшей мере пять, а по другую сторону – по меньшей мере шесть нулей. Следовательно, каждая исправляемая конфигурация ошибок может быть с помощью циклических сдвигов приведена к одному из трех следующих видов( позиции нумеруются числами от 0 до 22 ):
- все ошибки (не более трех) расположены в 11 старших разрядах;
- одна ошибка занимает пятую позицию, а остальные расположены в 11 старших разрядах;
- одна ошибка занимает шестую позицию, а остальные расположены в 11 старших разрядах.
Таким образом, в декодере надо заранее вычислить величины
s5 (x) = R g (x) [x 11 ∙ x5] и s6 (x) = R g (x) [x 11 ∙ x6] .
Тогда ошибка вылавливается, если вес s (x) не превышает 3 или если вес s (x) – s5 (x) либо s (x) – s6 (x) не превышает 2. В декодере можно либо исправлять все три ошибки, если эти условия выполнены, либо исправлять только две ошибки в младших 11 битах, дожидаясь удаления из принятого кодового слова третьего ошибочного бита.
Разделив x16 и x17 на порождающий многочлен
g (x) = x11 + x10 + x6 + x5 + x4 + x2 + 1,
имеем
s5 (x) = x9 + x8 + x6 + x5 + x2 + x ,
s6 (x) = x10 + x9 + x7 + x6 + x3 + x2 .
Следовательно, если ошибка содержится в пятой или шестой позициях, то синдром соответственно равен (01101100110) или (11011001100). Наличие двух дополнительных ошибок в 11 старших разрядах приводит к тому, что в соответствующих позициях два из этих битов заменяются на противоположные.
Декодер отслеживает синдром, отличающийся от нулевого синдрома не более чем в трех позициях, а также синдром, отличающийся от выписанных двух синдромов не более чем в двух позициях. Вычисление других синдромов говорит о наличие четырех ошибок в принятом кодовом слове, так как наличие пяти или более ошибок в принятом кодовом слове приводит к переходу в другую кодовую комбинацию, содержащую ошибки. Следовательно при наличии четырех ошибок в принятом кодовом слове происходит отказ от декодирования, и данное слово затирается нулями, что приводит к появлению стертых символов в кодовом слове внешнего кода.
ГЛАВА 5. КОДЫ БЧХ
5.1. Определение кодов БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) представляют собой обширный класс кодов, способных исправлять несколько ошибок и занимающих заметное место в теории и практике кодирования. Интерес к кодам БЧХ определяется по меньшей мере следующими тремя обстоятельствами :
- Среди кодов БЧХ при небольших длинах существуют хорошие коды.
- Известны относительно простые и конструктивные методы их кодирования и декодирования.
- Коды Рида—Соломона, являющиеся широко известным подклассом недвоичных кодов, обладают определенными оптимальными свойствами и прозрачной весовой структурой.
Определим исправляющие t ошибок коды БЧХ над GF (q) длины qm – 1, задавая порождающий многочлен g (х). Коды такой длины называют примитивными кодами БЧХ.
Пусть GF(q) – некоторое поле, пусть GF(Q) – расширение поля GF(q), и пусть b — элемент GF(Q). Простой многочлен f (x) наименьшей степени над GF(q), для которого f (b) = 0, называется минимальным многочленом элемента b над GF(q).
Тогда порождающий многочлен циклического кода можно представить в виде :
g (х) = НОК [f1 (х), f2 (х), … , fr (х)], (5.1)
где f1 (х), f2 (х), … , fr (х) – минимальные многочлены корней g (х).
Следовательно код БЧХ можно построить по порождающему многочлену, который будет задаваться своими корнями.
Пусть с (х) — кодовый многочлен, а е (х) — многочлен ошибок, тогда принятый многочлен с коэффициентами из GF (q) запишется в виде :
v (х) = с (х) + е (х). (5.2)
Можно вычислить значение этого многочлена на элементах из GF (qm), в частности, значения многочлена в точках, являющихся корнями g (х), например в точках γ1,…, γr. Тогда поскольку с (γj) = 0 для любых γj, являющихся корнями g (х), то
v (γj) = с (γj) + е (γj) = е (γj) . (5.3)
Таким образом,
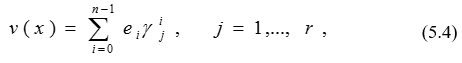
для всех γj, являющихся корнями g (x). В результате мы получаем r уравнений, содержащих только величины, определяемые ошибками и не зависящие от кодового слова. Если эти уравнения можно разрешить относительно ei , то можно определить многочлен ошибок. Нужно выбрать gj таким образом, чтобы система r уравнений могла быть решена относительно ei каждый раз, когда не более t неизвестных отличны от нуля.
Определим компоненты синдрома для произвольного циклического кода с порождающим многочленом g (х), имеющим корни g1,…, gr :
Sj = v(gj), j = 1, …, r . (5.5)
Эти элементы поля отличны от синдромного многочлена s (х), но содержат эквивалентную информацию. Можно подобрать g1,…, gr так, чтобы по S1, …, Sr можно было найти t ошибок. Если a — примитивный элемент поля GF (qm), то таким множеством является :
{a, a2, a3, …, a2 t}.
Выберем многочлен g (х) с указанной последовательностью корней. Задав длину n = qm – 1 примитивного кода для некоторого m и число t ошибок, которое необходимо исправить, поступим следующим образом:
1) выберем примитивный многочлен степени m и построим поле GF (qm) ;
2) найдем минимальные многочлены fj (х) для aj , j = 1,…, 2t ;
3) положим g (х) = НОК [f1 (х), f2 (х), … , fr (х)].
Такой циклический код может исправлять t ошибок. Иногда построенные таким образом коды БЧХ могут исправлять более t ошибок. Поэтому величина
d = 2t + 1 (5.6)
называется конструктивным расстоянием кода. Истинное минимальное расстояние кода d* может быть больше конструктивного.
Теперь дадим формальное определение кода БЧХ. Оно будет более общим, чем данное выше определение примитивного кода БЧХ, так как в качестве корней g (x) будут браться 2t последовательных степеней произвольного элемента b поля (не обязательно примитивного элемента). Длина кода будет равна порядку элемента b, т. е. такому наименьшему n, для которого b n = 1.
Пусть заданы q и m , и пусть b — любой элемент GF (qm) порядка n. Тогда для любого положительного целого числа t и любого целого числа j0 соответствующий код БЧХ является циклическим кодом длины n с порождающим многочленом
g (х) = НОК [f j 0 (х), f j 0+1 (х), … , f j 0+2 t-1(х)], (5.7)
где f j (х) — минимальный многочлен элемента bj.
Часто выбирают j0 = 1, что, как правило, (но не всегда), приводит к многочлену g (x) с наименьшей степенью. Обычно требуется большая длина кода, и тогда выбирается элемент b поля с наибольшим порядком, то есть примитивный элемент.
5.2. Коды Рида – Соломона
Важным и широко используемым подмножеством кодов БЧХ являются коды Рида—Соломона. Это такие коды БЧХ, у которых мультипликативный порядок алфавита символов кодового слова делится на длину кода. Таким образом, m = 1 и поле символов GF (q) совпадает с полем локаторов ошибок GF (qm). Обычно a выбирается примитивным; тогда
n = qm – 1 = q – 1.
Минимальный многочлен над GF (q) элемента b, взятого из того же поля, равен
fb(x) = x – b . (5.8)
Поскольку поле символов и поле локаторов ошибок совпадают, все минимальные многочлены линейны. В коде Рида-Соломона, исправляющем t ошибок, обычно полагается j0 = 1, и тогда порождающий многочлен записывается в виде
g (x) = (x – a)(x – a2)…(x – a2 t). (5.9)
Степень этого многочлена всегда равна 2t, откуда следует, что параметры кода Рида—Соломона связаны соотношением
n — k = 2t. (5.10)
В коде Рида—Соломона можно выбрать также любое другое значение j0, причем с помощью разумного выбора j0 иногда удается упростить кодер. Таким образом,
g (х) = (x – aj 0)(x – aj 0+1 )…(x – aj 0+2 t-1). (5.11)
Коды Рида—Соломона являются оптимальными в смысле границы Синглтона. Код Рида—Соломона имеет минимальное расстояние п — k + 1 и является кодом с максимальным расстоянием.
Конструктивное расстояние кода d = 2t + 1 . Минимальное расстояние d* удовлетворяет неравенству
d* ³ d = 2t+ 1 = n – k + 1,
поскольку для кодов Рида—Соломона 2t = n – k . Но для любого линейного кода имеет место граница Синглтона
d* £ n – k +1.
Следовательно, d* = n – k + 1 и d* = d.
Следовательно при фиксированных n и k не существует кода, у которого минимальное расстояние больше, чем у кода Рида-Соломона. Этот факт является веским основанием для использования кода Рида-Соломона.
ГЛАВА 6. АЛГОРИТМ БЕРЛЕКЭМПА – МЕССИ
6.1. Алгоритм Берлекэмпа – Месси
Теорема алгоритма Берлекэмпа – Месси. Пусть заданы S1,…,S2 t из некоторого поля, и пусть при начальных условиях L(0) (x) =1, B(0) (x) = 1 и L0 = 0 выполняются следующие рекуррентные равенства, используемые для вычисления L(2 t) (x):
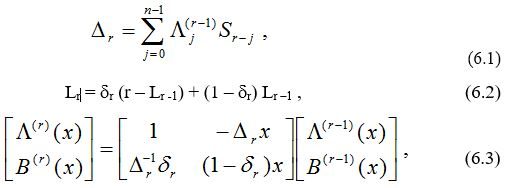
r = 1,…, 2t , где dr = 1, если одновременно Dr ¹ 0 и 2Lr – 1 £ r – 1 , и dr = 0 в противном случае. Тогда L(2 t) (x) является многочленом наименьшей степени, коэффициенты которого удовлетворяют равенствам
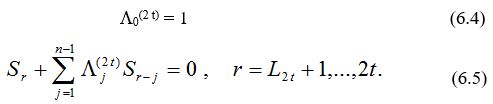
В этой теореме Dr может равняться нулю, но только в том случае, когда dr = 0. Тогда по определению Dr-1dr = 0.
В каждой итерации для умножения матриц требуется не более 2t умножений, а для вычисления Dr – не более t умножений. Всего производится 2t итераций, так что делается не более 6t2 умножений.
Вычисление многочлена локаторов ошибок использует алгоритм Берлекэмпа – Месси. По заданным Sj, j = 1,…, 2t , находится вектор L минимальной длины, удовлетворяющий t уравнениям
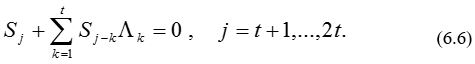
Это означает, что требуется по заданным 2t компонентам вектора S из свертки вычислить вектор L, если известно, что Lj = 0 при j > t . Удовлетворяющий этому равенству вектор L определяет коэффициенты многочлена локаторов ошибок
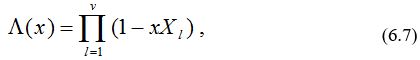
где Xl , l = 1,…,v, являются локаторами ошибок.
На рисунке 6.1 приведена блок–схема алгоритма Берлекэмпа–Месси.