3.3. Описание хода разработки
3.3.1. Информационная модель и ее описание
Информационная модель представляет собой схему движения входных, промежуточных и результативных потоков и функций предметной области. Кроме того, она объясняет, на основе каких входных документов и какой нормативно-справочной информации происходит выполнение функций по обработке данных и формирование конкретных выходных документов.
В качестве информационной модели будем использовать схему данных (ГОСТ 19.701-90). Схемы данных отображают путь данных при решении задач и определяют этапы обработки, а также различные применяемые носители данных. Схема данных состоит из следующих элементов:
- символов данных (символы данных могут также указывать вид носителя данных);
- символов процесса, который следует выполнить над данными (символы процесса могут также указывать функции, выполняемые вычислительной машиной);
- символов линий, указывающих потоки данных между процессами и (или) носителями данных;
- специальных символов, используемых для облегчения написания и чтения схемы.[1]
Весь цикл обработки информации можно разбить на два этапа:
- Прием, обработка и ввод первичной входящей информации (паспортные данные, реквизиты организаций и т.д.).
- Формирование документов (списков клиентов и т.д.).
Графическое представление информационной модели отражено на рис. 4.
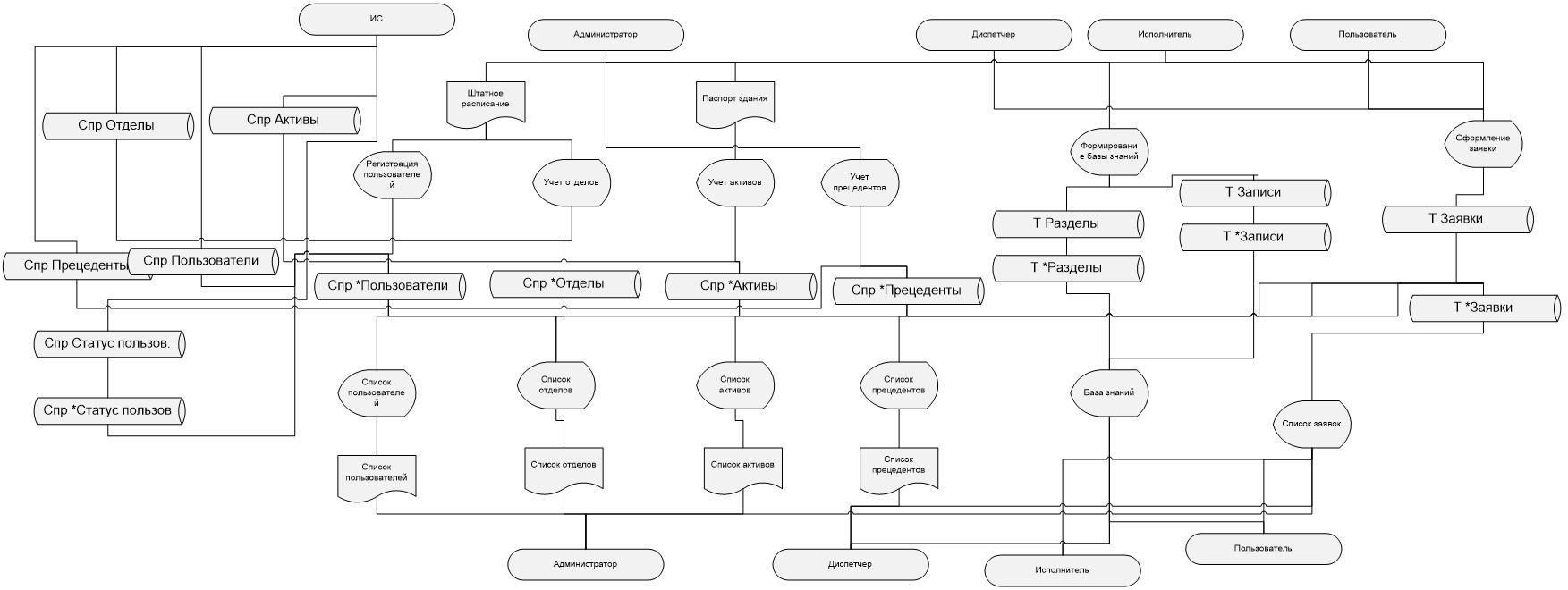
3.3.2 Характеристика нормативно-справочной, входной и оперативной информации
Входной информацией для проектируемой системы Help Desk являются заявки пользователей, сведения о сотрудниках предприятия, содержащиеся в штантном расписании, сведения о кабинетах здания, в котором располагается предприятие (паспорт здания), а также сведения о наиболее часто происходящих инцидентах, формируемые на основании опытной эксплуатации и сведения об отделах предприятия. Эти данные поступают как в цифровом, так и в печатном виде.
Данные из входных документов вносятся в систему путём ручного ввода данных через веб-интерфейс.
Из штатного расписания в систему вводятся следующие данные:
- ФИО пользователя;
- Наименование структурного подразделения.
Из атрибутов паспорта здания вносятся следующие реквизиты:
- номер кабинета;
- его принадлежность (по отделам).
Сведения об инцидентах, а также сведения об отделах содержат только наименования данных реквизитов.
Основным документом, вносимым в систему, является заявка пользователей на техническую поддержку.
Данный документ содержит следующие реквизиты:
- наименование заявки;
- описание заявки;
- категория ( инцидент);
- приоритет;
- номер кабинета;
- файл с ошибкой;
- комментарий к заявке.
Для обеспечения работы системы предусмотрены справочники, приведенные в таблице 8
Таблица 8 Перечень используемых справочников
| № пп | название справочника | ответственный за ведение | средний объём справочника в записях | среднюю частоту актуализации | средний объем актуализации, % |
| 1. | Отделы | Администратор | 45 | 1 раз в месяц | 10 |
| 2. | Активы | Администратор | 150 | 1 раз в год | 10 |
| 3. | Прецеденты | Администратор | 10 | 1 раз в месяц | 10 |
| 4. | Пользователи | Администратор | 250 | 1 раз в год | 10 |
| 5. | Статусы пользователей | Администратор | 5 | 1 раз в год | 10 |
| 6. | ПК | Администратор | 10 | 1 раз в месяц | 10 |
| 7. | Материнские платы | Администратор | 10 | 1 раз в месяц | 10 |
| 8. | Клавиатуры | Администратор | 10 | 1 раз в месяц | 10 |
| 9. | Мыши | Администратор | 10 | 1 раз в месяц | 10 |
| 10. | Веб-камеры | Администратор | 10 | 1 раз в месяц | 10 |
| 11. | ОЗУ | Администратор | 10 | 1 раз в месяц | 10 |
| 12. | Корпус | Администратор | 10 | 1 раз в месяц | 10 |
| 13. | Блок питания | Администратор | 10 | 1 раз в месяц | 10 |
| 14. | Процессор | Администратор | 10 | 1 раз в месяц | 10 |
| 15. | Жесткий диск | Администратор | 10 | 1 раз в месяц | 10 |
| 16. | Видеокарта | Администратор | 10 | 1 раз в месяц | 10 |
Справочник Отделы формируется на основании штанного расписания и содержит только наименование отдела. На основании этого же документа формируется и справочник Пользователи. Справочник Активы формируется на основании паспорта здания, а Справочник Прецеденты – на основании результатов анализа опытной эксплуатации (работы службы техподдержки). Справочник Пользователи формируется на основании штатного расписания предприятия, а также Справочника Статусы пользователей в системе. В справочнике ПК содержаться сведения о конфигурациях персональных компьютеров. Остальные справочники, приведенные в таблице 4 под номерами 7-18, содержать только наименования соответствующих комплектующих.
3.3.3 Характеристика результатной информации
Основным результатным документом для разработанной системы Help Desk является список заявок пользователей, распределенный по следующим статусам:
- новые;
- распределенные;
- в процессе;
- на проверке;
- закрытые;
- удаленные.
Реквизиты данного документа следующие:
- Номер заявки по порядку в списке;
- Регистрационный номер заявки;
- Статус;
- Приоритет;
- Файл, присоединенный к заявке.
- Дата последнего изменения статуса заявки;
- ФИО пользователя, открывшего заявку;
- Отдел пользователя;
- Наименование заявки;
- Описание, Актив;
- Категории (прецеденты);
- Комментарий.
Данные реквизиты являются общими для всех заявок. Для заявок, перешедших в статус Распределена и дальше (кроме статуса Удалена) предусмотрены также следующие реквизиты:
- сведения об исполнителе, в том числе:
- ФИО исполнителя;
- должность исполнителя.
- сведения о жизненном цикле заявки, в том числе дата и время изменения каждого статуса.
Кроме того, для удобства работы администратора формируются следующие выходные документы:
- список пользователей с возможностью редактирования;
- список отделов;
- список активов;
- список конфигураций ПК;
- список прецедентов.
Документ «Список пользователей» содержит следующие реквизиты:
- номер пользователя в системе;
- ФИО пользователя;
- Статус пользователя;
- Отдел пользователя;
- конфигурация ПК;
- логин;
- пароль.
Данный документ формируется на основе таблиц Пользователи, Отделы, а также справочника Статусы пользователей.
Выходной документ Список отделов содержит только наименование отдела и формируется на основании соответствующего справочника.
Выходной документ Список активов содержит наименование отдела, номер кабинета и формируется на основании соответствующего справочника.
Выходной документ Список прецедентов содержит только наименование прецедента и формируется на основании соответствующего справочника.
3.3.4. Общие положения (дерево функций и сценарий диалога)
В разработанной системе предусмотрены 4 вида пользователей:
- администратор системы, обладающий наиболее полными полномочиями при работе с системой;
- диспетчер, распределяющий заявки;
- исполнитель, принимающий и закрывающий заявки;
- пользователь системы, подающий заявки.
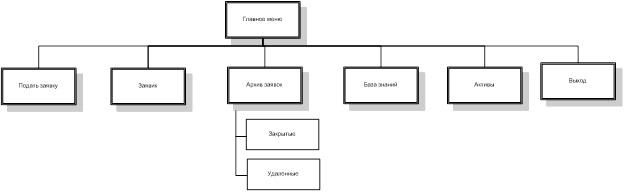
Более подробно функции данных пользователей приведены на рисунках 3-6.
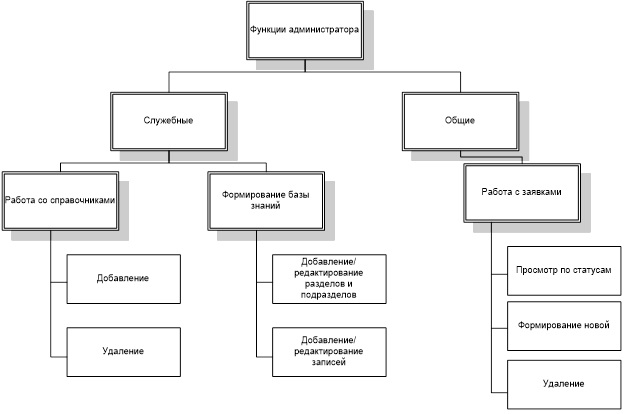
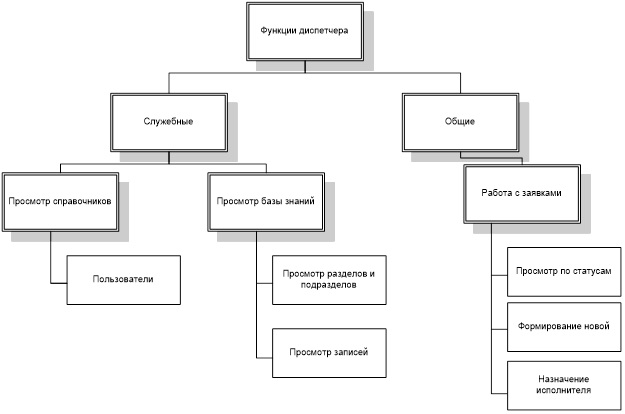
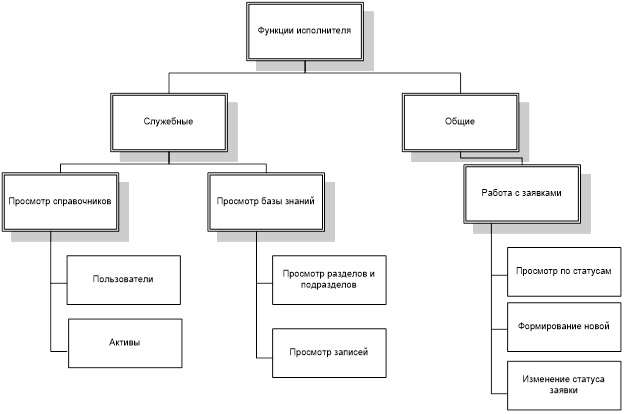
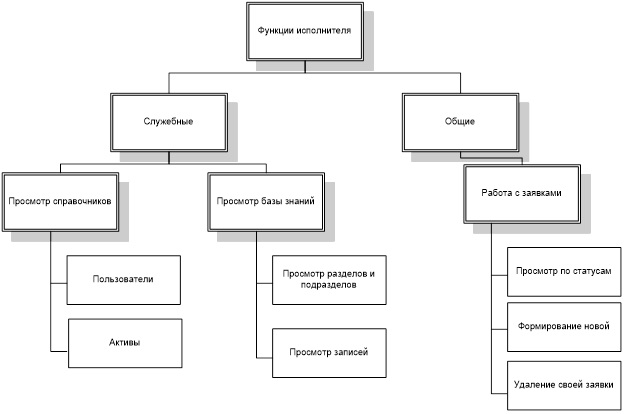
На основании данных функций формируется сценарий диалога, схема которого для каждого из пользователей представлена на рисунках 8-11.
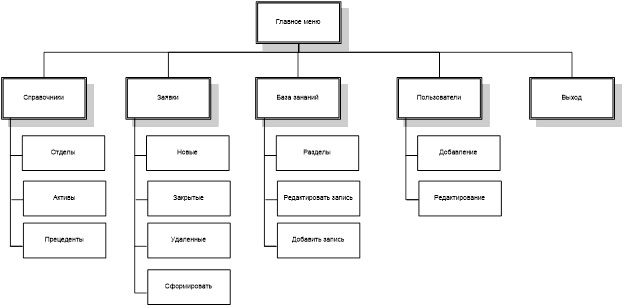
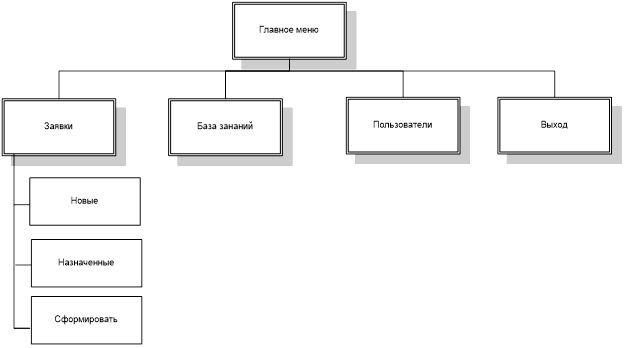
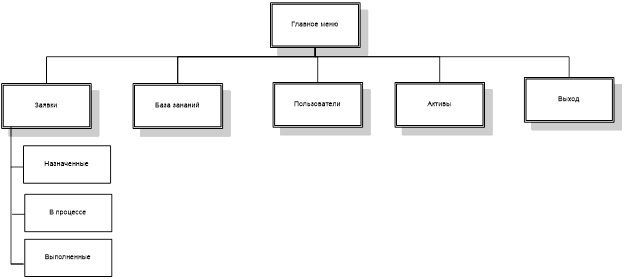
3.3.5. Характеристика базы данных
Инфологическая (концептуальная) модель — это формализованное описание предметной области, выполненное безотносительно к используемым в дальнейшем программным и техническим средствам.[3] Инфологическая модель должная быть динамической и позволять легкую корректировку. К основным требованиями, предъявляемым к инфологической модели, можно отнести следующие:
- инфологическая модель должна содержать всю необходимую и достаточную информацию для последующего проектирования базы данных;
- инфологическая модель должная быть понятна лицам, принимающим участие в создании системы.
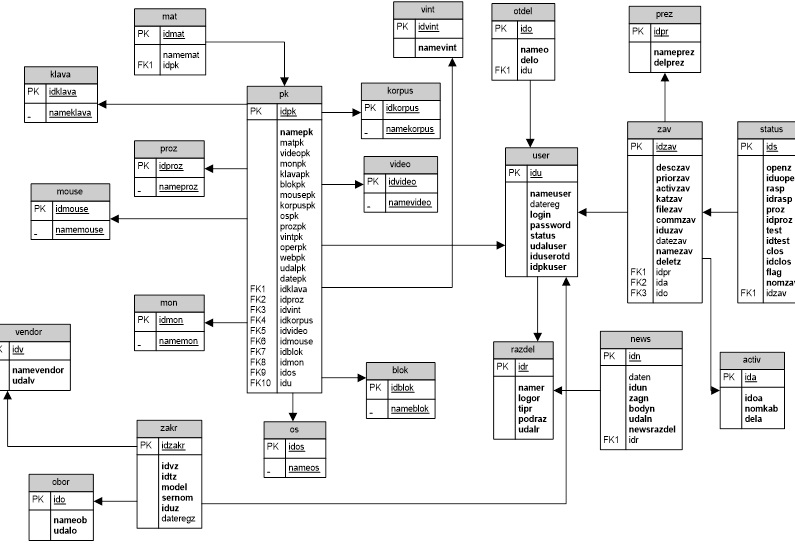
ER-модель представляет собой логическую структуру информации об объектах системы. Компонентами ER-модели являются сущности (объекты) и отношения (связи между объектами). Объект имеет множество реализаций или экземпляров. Экземпляр объекта образуется совокупностью конкретных значений реквизитов и должен однозначно определяться, т.е. идентифицироваться значением ключа объекта, который состоит из одного ли нескольких ключевых реквизитов.
Сущности могут быть зависимыми и независимыми. Сущность является независимой, если каждый экземпляр ее может быть однозначно идентифицирован без определения ее отношений с другими сущностями. Однозначная идентификация экземпляра зависимой сущности зависит от отношений с другими сущностями.
Для отображения отношений между сущностями используются связи. Связи существуют, если экземпляры сущностей логически взаимосвязаны.
ER-модель разработанной базы данных представлена на рисунке 12.
Далее определим для каждой таблицы тип поля и формат содержащихся в нем данных.
Таблица 9. Структура таблицы zav
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код записи | idzav | int(10) | auto_increment |
| 2. | Описание заявки | desczav | text | |
| 3. | Приоритет | priorzav | int(1) | |
| 4. | Актив | activzav | int(2) | |
| 5. | Категория | katzav | int(2) | |
| 6. | Ссылка на прикрепленный файл | filezav | text | |
| 7. | Комментарий | commzav | text | |
| 8. | Код добавившего пользователя | iduzav | int(3) | |
| 9. | Дата формирования | datezav | timestamp | |
| 10. | Наименование | namezav | varchar(255) | |
| 11. | Флаг удаления | deletz | int(1) |
Таблица 10. Структура таблицы activ
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код записи | ida | int(1) | auto_increment |
| 2. | Код отдела | idoa | int(2) | |
| 3. | Номер кабинета | nomkab | varchar(6) | |
| 4. | Флаг удаления | dela | int(1) |
Таблица 11. Структура таблицы status
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код записи | ids | int(10) | auto_increment |
| 2. | Дата и время открытия | openz | varchar(45) | |
| 3. | Код пользователя | iduopen | int(2) | |
| 4. | Дата и время распределения | rasp | varchar(45) | |
| 5. | Код пользователя | idrasp | int(2) | |
| 6. | Дата и время приема | proz | varchar(45) | |
| 7. | Код пользователя | idproz | int(2) | |
| 8. | Дата и время проверки | test | varchar(45) | |
| 9. | Код пользователя | idtest | int(2) | |
| 10. | Дата и время закрытия | clos | varchar(45) | |
| 11. | Код пользователя | idclos | int(2) | |
| 12. | Флаг удаления | flag | int(1) | |
| 13. | Номер заявки | nomzav | int(3) |
Таблица 12. Структура таблицы user
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код сотрудника | idu | int(11) | auto_increment |
| 2. | ФИО сотрудника | nameuser | varchar(25) | |
| 3. | Дата регистрации | datereg | timestamp | |
| 4. | Логин для доступа в систему | login | varchar(25) | |
| 5. | Пароль для доступа в систему | password | varchar(25) | |
| 6. | Дата рождения | status | int(1) | |
| 7. | Флаг удаления | udaluser | int(1) | |
| 8. | Код отдела | iduserotd | int(1) |
Таблица 13. Структура таблицы news
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код записи | idn | int(11) | auto_increment |
| 2. | Дата | daten | timestamp | |
| 3. | Код пользователя | idun | int(10) | |
| 4. | Заголовок | zagn | varchar(255) | |
| 5. | Тело записи | bodyn | text | |
| 6. | Флаг удаления | udaln | int(1) | |
| 7. | Номер раздела | newsrazdel | varchar(12) |
Таблица 14. Структура таблицы razdel
| № | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код раздела | idr | int(100) | auto_increment |
| 2. | Наименование | namer | varchar(100) | |
| 3. | Логотип | logor | varchar(255) | |
| 4. | Тип раздела | tipr | int(1) | 1 – основной, 2 — подраздел |
| 5. | Номер основного раздела | podraz | int(10) | При наличии |
| 6. | Флаг удаления | udalr | int(1) |
Таблица 15. Структура таблицы otdel
| № пп | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код отдела | ido | int(1) | |
| 2. | Наименование | nameo | varchar(255) | |
| 3. | Флаг удаления | delo | int(1) |
Таблица 16. Структура таблицы prez
| № пп | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код прецедента | idpr | int(1) | |
| 2. | Наименование | nameprez | varchar(255) | |
| 3. | Флаг удаления | delprez | int(1) |
Таблица 17. Структура таблицы Pk
| № пп | Наименование поля | Идентификатор | Тип | Примечание |
| 1. | Код | idpk | int(11) | |
| 2. | Наименование конфигурации | namepk | varchar(255) | |
| 3. | Материнская плата | matpk | int(11) | |
| 4. | Видеокарта | videopk | int(11) | |
| 5. | Монитор | monpk | int(11) | |
| 6. | клавиатура | klavapk | int(11) | |
| 7. | Блок питания | blokpk | int(11) | |
| 8. | мышь | mousepk | int(11) | |
| 9. | Корпус | korpuspk | int(11) | |
| 10. | ОС | ospk | int(11) | |
| 11. | Процессор | prozpk | int(11) | |
| 12. | Жесткий диск | vintpk | int(11) | |
| 13. | ОЗУ | operpk | int(11) | |
| 14. | Веб-камера | webpk | int(11) | |
| 15. | Отметка об удалении | udalpk | int(11) | |
| 16. | Дата записи | datepk | timestamp |
Таблица 18. Структура таблицы Zakr
| № пп | Наименование поля | Идентификатор | Тип | Примечание |
| 1 | Код | idzakr | int(11) | |
| 2 | Код производителя | idvz | int(11) | |
| 3 | Код типа оборудования | idtz | int(11) | |
| 4 | Модель | model | varchar(255) | |
| 5 | Серийный номер | sernom | varchar(150) | |
| 6 | Код пользователя | iduz | int(11) | |
| 7 | Дата регистрации | dateregz | timestamp |
Остальные таблицы базы данных содержат только наименование реквизита и отметку об его удалении.
Разработанная база данных находится в в третьей нормальной форме (нормальной форме Бойса-Кодда), так как каждый ее атрибут, от которого другие атрибуты зависят функционально полно, будет являться возможным ключом данной таблицы.
Дальнейшая нормализация не оправдана, так как при перевода базы данных в высшие нормализованные формы придется расплачиваться увеличением затрат на обслуживание БД.
Затраты включают в себя физические аспекты, такие как дисковое пространство, ресурсы, необходимые для управления этой структурой, и утраченные возможности из-за временных задержек, связанных с обслуживанием этого процесса.
Для того, чтобы база данных корректно работала при любом уровне нагрузки (количестве запросов в единицу времени), необходимо оптимизировать использование ресурсов сервера баз данных.
Как правило, в серверах баз данных существуют следующие проблемные места, которые можно решить выполнением специализированных мероприятий:
- Поиск данных на диске. Чтобы найти на диске какой-то фрагмент данных, требуется некоторое время. Для устройств выпуска 2013 года среднее время поиска составляет менее 10мс, так что теоретически можно выполнять приблизительно 100 операций поиска в секунду. Это время можно ненамного уменьшить, заменив диски более новыми. Для одной таблицы поиск на диске оптимизировать очень сложно. Такую оптимизацию можно выполнить путем распределения данных по нескольким дискам.
- Дисковое чтение/запись. После выполнения поиска, когда найдена соответствующая позиция на диске, мы можем считать данные. Для устройств выпуска 2013 года производительность одного диска составляет около 10-20Мб/с. Дисковое чтение/запись легче оптимизировать, чем дисковый поиск, поэтому читать можно параллельно с нескольких дисков.
- Пропускная способность ОЗУ (memory bandwidth). Когда процессору требуется больше данных, чем может вместить его кэш, узким местом становится пропускная способность памяти. В большинстве систем это узкое место встречается редко, однако о нем нужно знать.
Кроме того, предприняты следующие меры:
- Оптимизирована структура таблиц базы данных;
- Определен лимит времени соединения (2 минуты) с базой данных в отсутствие активной деятельности пользователя;
- Использован минимально необходимый объем полей в таблицах базы данных;
- Использованы индексы в таблицах;
- Использованы различные приоритеты при выполнении различных типов запросов (для SELECT – LOW_PRIORITY, для INSERT и UPDATE – HIGH_PRIORITY);
- Использованы RAID-массивы для хранения данных;
- Использованы постоянные соединения с базой данных, что позволяет уменьшить время на подключение/отключение соединения;
- Настроен сам сервер баз данных.