или напишите нам прямо сейчас:
⚠️ Пожалуйста, пишите в MAX или заполните форму выше.
В России Telegram и WhatsApp блокируют - сообщения могут не дойти.
3 Проектирование программного обеспечения компьютерного зрения
3.1 Выбор программных средств реализации поставленной задачи
или напишите нам прямо сейчас:
⚠️ Пожалуйста, пишите в MAX или заполните форму выше.
В России Telegram и WhatsApp блокируют - сообщения могут не дойти.
Для выбора языка программирования сравним следующие языки – C++, Delphi и C#[1].
Сравнение языков программирования приведено в Таблице 2.
Таблица 2 — Сравнение языков программирования
| Параметр | Степень соответствия, % | ||
| Delphi | C++ | C# | |
| Возможность компиляции | 8 | 8 | 4 |
| Многопоточная компиляция | 8 | 0 | 8 |
| Интерпретатор командной строки | 6 | 4 | 0 |
| Многомерные массивы | 8 | 0 | 8 |
| Динамические массивы | 8 | 8 | 0 |
| Ассоциативные массивы | 4 | 0 | 0 |
| Интерфейсы | 8 | 0 | 4 |
| Мультиметоды | 8 | 0 | 0 |
| Общая оценка | 7,25 | 2,5 | 3 |
При выборе программного обеспечения для разработки приложения будем обращать внимание на такие характеристики как:
- надёжность
- эффективность
- стоимость
- понятность пользователю
- простота настройки
- простота оформления экранных и печатных форм [2]
При выборе IDE для разработки приложения будут рассмотрены:
- Microsoft Visual C# 2008 Express Edition;
- Delphi 7.
Microsoft Visual C# 2008 Express Edition является мощной системой программирования, позволяющей быстро и эффективно создавать приложения для Microsoft Windows.
C# — является типизированным, объектно-ориентированным, простым и в то же время мощным языком программирования, позволяющий разработчикам создавать различные многофункциональные приложения. С использованием возможностей .NET Framework Visual C# 2008 позволяет создавать приложения под платформу Windows, веб-службы, а также инструменты, компоненты и элементы управления базами данных, и многое другое.
Delphi 7 можно назвать знакомой средой для визуальной разработки, основанной на Object Pascal. Этот пакет имеет поддержку новейших перспективных технологий веб-служб. Несет в себе предварительную версию средств для работы с Microsoft .NET Framework. Благодаря Delphi 7 разработчики, применяющие Delphi, могут получить дополнительные навыки программирования для .NET, отлаживать свои приложения для работы под управлением .NET, не теряя при этом навыков и знаний в области проектирования под Windows.
Характерной чертой пакета становится полная поддержка уже созданных и новый Web-сервисов, встроенная модельно-управляемая разработка и возможность предварительного просмотра для Microsoft .NET Framework. Применяя Delphi 7 Studio более 1 миллиона разработчиков, программирующих на Delphi, могут уже сейчас улучшать своих навыки работы с .NET и реализовывать приложения для .NET с применением уже созданных наработок и навыков взаимодействия на Windows-платформу.
Для разработки информационной системы был выбран язык программирования Delphi.
Основные преимущества и возможности Borland Delphi 7 Studio заключаются в:
- Создание корпоративных приложений с применением MDA — упрощает процесс создания, позволяя разработчикам ускорять процесс от проектирования к установке, минимизируя количество кода и времени, нужного для разработки;
- RAD Visual Web Development — позволяет визуально разрабатывать Web-приложения в среде Delphi 7 Studio и исключает задачи создания общего сервера Application Mode;
- Встроенная межплатформенная поддержка Linux — Delphi 7 Studio будет идти в комплекте с Delphi language version of Borland Kylix 3, первой высокоэффективной, визуальной средой разработки (IDE) для упрощенного создания БД, GUI-, Web-приложений, а также Web-сервисов для ОС Linux;
- Доступность составления отчетов в рамках компании — позволяет разработчикам реализовывать межплатформенные отчеты, определяя эффективность функционирования программ;
- Royalty-Free DataSnap Multi-tier Application Deployment (ранее MIDAS) — обновленное лицензирование гарантирует разработчикам целостных, одиночных, клиент-серверных и многоуровневых приложений реализовать разработку без скрытой платы за все время рабочего использования;
- Создание ПО для Windows XP — Delphi 7 Studio имеет поддержку Windows XP Theme, позволяющую разработчикам разрабатывать ПО, использующее положительные стороны интерфейса Windows XP User.
Для разработки приложения будет использоваться среда разработки RAD Studio Professional.
RAD Studio Professional это мощная IDE включающая в себя:
- интегрированные среды разработки разнообразных приложений под Windows и .NET.
- Интегрированную среду для разработки Delphi
- C++Builder с поддержкой Unicode
Для удобной разработки собственных приложений среда разработки включает в себя сотни различных готовых компонентов и функций, таких как:
- Рефакторинг;
- дополнение кода;
- выделение синтаксиса;
- интерактивные шаблоны;
- полнофункциональная отладка и тестирование модулей
Данная интегрированная среда разработки поддерживает разработку приложений для платформы .NET, включая в себя, поддержку самых последних технологий .NET.
Выбор СУБД представляет собой непростую многопараметрическую задачу и становится одним из самых ответственных этапов при создании приложений БД. Выбранный программный продукт должен отвечать и текущим, и будущим потребностям компании, поэтому важно учитывать денежные затраты на покупку нужного оборудования, самой системы, создание необходимого ПО на ее основе, а также проведение обучения сотрудников. Ещё нужно убедиться, что выбранная СУБД может реально принести компании какие-то выгоды.
При выборе СУБД будет опираться на следующие параметры: стабильность; цена; простота настройки.
При выборе СУБД рассматривались три кандидата:
- Microsoft SQL Server 2012;
- Microsoft Access;
- Oracle;
Microsoft SQL Server 2012 можно назвать совокупным, интегрированным сквозным решением, которое поддерживает организацию безопасной, надежной, и эффективной платформой для реализации обработки промышленных данных и приложений, относящихся к интеллектуальной собственности компании. Microsoft SQL Server 2012 поддерживает мощные, знакомые инструменты как для IT-специалистов, так и для работников IT-сферы, минимизирующие сложность разработки, установки, контроля и применения данных компании и аналитических приложений на платформах от портативных устройств до ИС компании. Благодаря полноценному набору функций, работе с существующими системами и автоматизации типовых задач, SQL Server 2012 позволяет находить решение в области сохранения информации для компаний любого масштаба.
Инструменты разработки: Microsoft SQL Server предлагает встроенные инструменты разработки для ядра БД, извлечения, изменения и загрузки данных, извлечения данных, OLAP и отчётности, которые взаимосвязаны с Microsoft Visual Studio для формирования сквозных возможностей создания ПО. Каждая главная подсистема SQL Server включает в себя собственную объектную модель и набор API для улучшения систем данных в любом направлении, что позволяет оптимально отражать ваш бизнес.
Платформа данных Microsoft SQL Server 2012 дает любой организации такие преимущества как:
- Применение активов данных;
- Увеличение продуктивности;
- Минимизация сложности информационных технологий;
- Уменьшение совокупной стоимость владения.
Microsoft Office Access или просто Microsoft Access представляет собой псевдо-реляционную система управления базами данных разработанная корпорацией Microsoft.
Осуществляет поддержку широкого спектра функций, таких как:
- имеет связанные запросы;
- присутствует связь с внешними таблицами и БД;
- Благодаря наличию языка vba, в самом приложении Access можно реализовывать приложения, работающие с БД;
Oracle Database или Oracle RDBMS является объектно-реляционной системой управления Oracle, занимает верхние строчки на рынке СУБД, а также лидирует на платформах Unix и Windows. В России также просматривается лидерство Oracle, особенно в рамках крупномасштабных ИС государственных структур. Фактически сейчас у нас СУБД Oracle является стандартом для государственных ИС.
Главным преимуществом Oracle перед остальными конкурентами (прежде всего перед SQLServer) является аналогия кода разных версий сервера БД Oracle для всех платформ, что дает идентичность и предсказуемость работы Oracle на любом ПК внутри сети, какие бы конфигурации не входили бы в нее. Все варианты сервера Oracle заключают в себе один и тот же исходный программный код и идентичны функционально, за исключением отдельных опций, которые, добавляются к Oracle Database Enterprise Edition и не включены в Oracle Database Standard Edition. Поэтому для всех платформ создана единая СУБД в различных версиях, которая одинаково работает предоставляет единую функциональность вне зависимости от базовой платформы, на которой она функционирует.
В Таблице 3 приведена таблица сравнения для трех распространенных систем управления базами данных, которые конкурируют на рынке программного обеспечения по основным показателям.
Таблица 3 Сравнение СУБД
| Показатели | MS Access | баллы | Microsoft SQL Server 2012 | баллы | Oracle | баллы |
| Поддерживаемые операционные системы | Windows Desktop/Server | 3 | Windows Desktop/Server , Linux, Unix, Mac | 5 | Windows1 Desktop/S22erver, Linux, Unix, 2Mac | 5 |
| Поддержка даты и времени | Да | 3 | Да (без временной зоны) | 2 | Да | 3 |
| Аутентификация | Средствами БД и ActiveDirectory | 3 | Средствами БД | 2 | Много разных методов, включающих предыдущие | 1 |
| Производительностьпланировщика запросов для сложных запросов | Средняя (умеет параллельные запросы «из коробки») | 1 | Очень хорошая | 5 | Плохая | 1 |
| Итого | 14 | 10 | 10 |
Таким образом, для разработки системы распознавания образов необходимо и достаточно разработать базу данных в среде СУБД Access 2010 [15].
3.2 Выбор и реализация алгоритмов, позволяющих решить поставленную задачу
3.2.1 Общий алгоритм для решения поставленной задачи
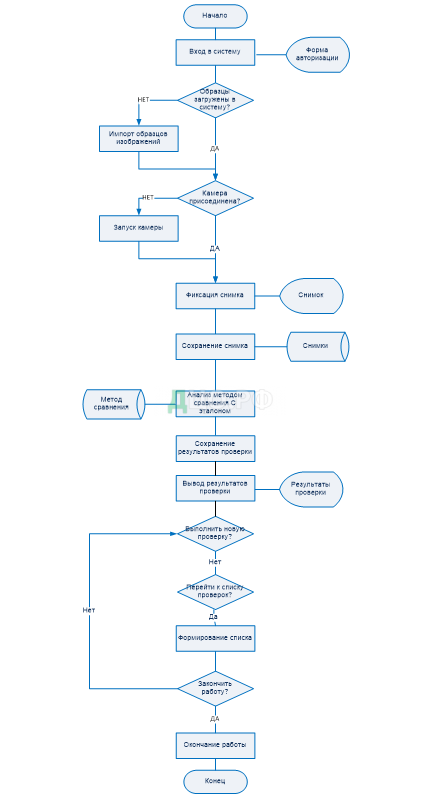
Основным алгоритмом работы системы является распознавание образа на основании метода сопоставления с эталоном. Алгоритм данного процесса приведен на рисунке 11.
Далее работа программы осуществляется в следующем порядке.
Результаты классификации
Результаты классификации представляются классом «TSearchInfo». Данный класс инкапсулирует в себе следующие данные:
- «ObjectID» — идентификатор образа, с которым производилось сравнение;
- «ClassID» — идентификатор класса, к которому принадлежит данный образ;
- «Similarity» — степень сходства входного изображения и образа (количество сходных точек);
- «Points» — список характеристических точек образа;
- «Matches» — список сходных точек (точки входного изображения сходные с точками образа);
- «ComputationTime» — время, затраченное на сравнение точек образа и точек входного изображения.
Класс «TAnalyser» активно использует данную структуру данных для хранения результатов вычислений.
Класс «TAnalyser» ведет историю вычислений (поле «FClassificationHistory : TStringList»). При выполнении классификации, экземпляр класса «TSearchInfo» создается для каждого образа, т.к. сравнение входного изображения производится с каждым образом, который имеется в базе данных.
Также класс «TAnalyser» содержит поле (FClassificationResult: TSearchInfo), которое хранит наилучший результат сравнения (максимальное количество сходных точек). Данное поле и является результатом классификации. Класс входного изображения определяется классом данного образа.
Сравнение точек
Сравнения точек производится по схеме «каждая с каждой». Для примера рассмотрим следующую ситуацию: у нас имеется набор точек входного изображения (279 точек) и набор точек образа (357 точек). В итоге придется выполнить 279*357=99603 сравнений «точка с точкой». А сходство двух точек определяется как среднее геометрическое (расстояние):
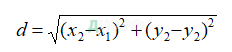
Но т.к. в нашем случае дескриптор точки представляет собой вектор из 64-х составляющих, то формула расчета расстояния между двумя точками будет представлена следующим образом:
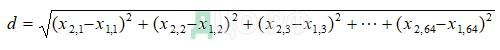
Алгоритм классификации
Алгоритм классификации входных изображений можно представить следующей формальной блок-схемой (рисунок 11). Работа алгоритма начинается с подачи на его вход изображения (входного изображения). После этого выполняется расчет точек входного изображения (ниже будет описан процесс вычисления точек изображения методом SURF). Следующим действием выполняется подготовка полей класса к сохранению результатов новой классификации. Поле этого выполняется запрос к базе данных, результатом которого является список всех идентификаторов образов, хранящихся в БД. Далее, в цикле выполняется перебор данного списка и последовательная выгрузка из базы данных точек образов. После выгрузки точек образа выполняется их сравнение с точками входного изображения. Полученные результаты сравниваются с предыдущими «лучшими» результатами (переменная выходного результата), и если предыдущие результаты хуже, то они перезаписываются текущими результатами.
После прохождения всего списка образов до конца, алгоритм завершает свою работу, а выходная переменная будет содержать результаты сравнения входного изображения и максимально идентичного образа. Класс входного изображения определяется классом образа. Данная схема реализована в методе «Classification» класса «TAnalyser» (рисунок 12).
Вычисления точек изображения методом SURF
Каждая найденная тока описывается классом «IPoint». Данный класс содержит поля (координаты точки, масштаб, дескриптор точки), которые в полной мере описывают характеристическую точку. Но т.к. на изображении может располагаться множество точек, то для хранения множества экземпляров класса «IPoint» используется список (класс «TStringList»).
Делее будет представлена блок-схема для алгоритма вычисления точек (рисунок 13). Блок-схема соответствует методу «function GetIPoints (B : TBitmap) : TStringList» класса «TAnalyser». Алгоритм начинается с загрузки входного изображения. Изображение представляется в виде битмапа. Создается переменная (экземпляр класса «TStringList») которая будет содержать результаты работы SURF.
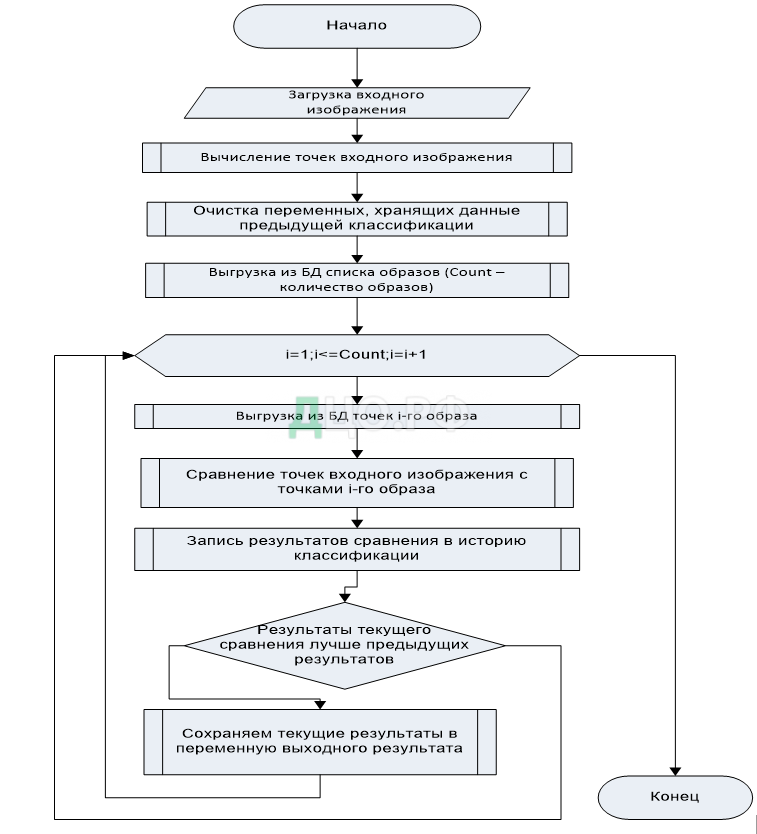
Для изображения вычисляется его интегральное представление, которое будет использоваться для дальнейших вычислений. Далее производится поиск особых точек (рисунок 13).
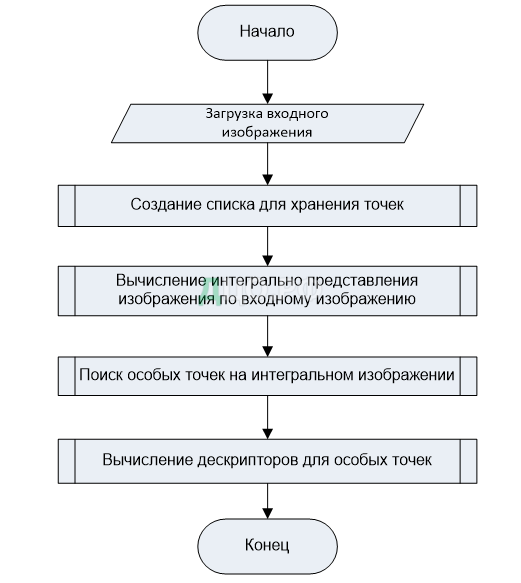
Завершающим этапом алгоритма является вычисление дескрипторов для найденных особых точек – описание особой точки и её окрестности при помощи метода SURF.
3.2.2 Выбор конкретных алгоритмов для решения соответствующих этапов основного алгоритма
В результате изучения алгоритмов распознавания и сравнение выбраны следующие — для распознавания выбран метод сравнения с эталонами, а для извлечения признаков метод SURF.
Распознаванием образов называют сравнение его с набором векторов-эталонов такой же размерности. Задача по распознаванию и принятию решений о принадлежности данного образа к тому или иному классу, основанная на анализе вычисленных признаков, имеет целый ряд строгих математических решений в рамках детерминистического и вероятностного подходов [12, 14].
В случае, если целью является создания системы для распознавания символьных образов, то для ее реализации наиболее часто используется классификация, основанная на подсчете евклидова расстояния между вектором признаков распознаваемого символа и векторами признаков эталонного описания. Качество распознавания в наибольшей степени зависит от типа и количества признаков. Так же во время анализа заранее подготовленного изображения происходит формирование вектора. Такой процесс называется извлечением признаков. Чтобы получить эталон для каждого класса следует провести аналогичную обработку символов для обучающей выборки [11].
Основными достоинствами признаковых методов являются:
- Простые в реализации;
- хорошая способность к обобщению;
- хорошая устойчивость к изменениям формы символов;
- низкое число отказов от распознавания;
- высокая скорость работы;
Наиболее серьезные недостатки данных методов:
- неустойчивость к различным дефектам изображения;
- на этапе извлечения признаков происходит необратимая потеря части информации о символе;
- Извлечение признаков ведется независимо, поэтому информация о взаимном расположении элементов символа утрачивается [12];
Поскольку четких правил для отбора признаков не может существовать, из-за чего методы разрабатываемые разными разработчиками систем распознавания могут оперировать абсолютно различными наборами признаков[13].
Алгоритм работает по следующему принципу. Для изображения сцены и изображения эталона с помощью метода SURF находятся особые точки и уникальные дескрипторы для них. При сравнении этих наборов дескрипторов, мы выделяем объект-эталон на сцене.
С помощью SURF решается две задачи — поиск особых точек изображения и создание их дескрипторов, которые инвариантны к масштабу и вращению.
Алгоритм SURF использует разномасштабные фильтры для нахождения гессианов [14].
После того как ключевые точки будут найдены, SURF сформирует их дескрипторы. Дескриптор представляет из себя набор из 64(128) чисел для каждой ключевой точки. Данные числа отображают флуктуации градиента вокруг ключевой точки. И поскольку ключевая точка представляет собой максимум гессиана, то это гарантирует, что в окрестности точки должны быть участки с разными градиентами. Таким образом, обеспечивается дисперсия (различие) дескрипторов для разных ключевых точек[15].
Флуктуации градиента окрестностей ключевой точки считаются относительно направления градиента вокруг точки в целом (по всей окрестности ключевой точки). Таким образом, достигается инвариантность дескриптора относительно вращения. Размер же области, на которой считается дескриптор, определяется масштабом матрицы Гессе, что обеспечивает инвариантность относительно масштаба.
Плюс к дескриптору, для описания точки используется знак следа матрицы Гессе, то есть величина sign(Dxx+Dyy). Для темных точек на светлом фоне – положителен, а для светлых точек на темном фоне, след отрицателен. Таким образом, SURF различает светлые и темные пятна.
После применения алгоритма SURF к изображению мы получаем набор дескрипторов который будет уникально идентифицировать эталон на сцене.
Достоинствами метода являются[16]:
1) Инвариантен к поворотам и масштабированию;
2) Инвариантен к разнице общей яркости изображений;
3) Может детектировать более 1 объекта на сцене;
Недостатки метода:
1) Весьма сложный в реализации;
2) Скорость работы алгоритма относительно медленная;
3.3 Проектирование структуры проекта программного обеспечения
3.3.1 Разработка базы данных для эталонных изображений
При разработке базы данных согласно методике предложенной [12] обычно выделяется некоторое количество этапов, с помощью которых осуществляется переход от предметной области к созданию базы данных средствами выбранной СУБД [8].
Перечислим основные этапы [17]:
Анализ предметной области.
- Определение основных объектов (сущностей) предметной области, выявляют их атрибуты и взаимосвязи между собой.
- Определение примерного состава информационного фонда [3].
Информационный анализ класса задач.
- Анализ внешних моделей данных, которые используются в программе.
- Анализ источников и возможностей для формирования информационного фонда
Построение инфологической модели предметной области.
- Выбор наиболее адекватной модели для описания предметной области.
- Графическое изображение модели.
- Формирование требований к СУБД и ограничений
Выбор конкретной СУДБ. Выбор СУБД – претендентов.
- Сравнение возможностей СУБД-претендентов с учетом требований и ограничений[18].
- Анализ возможностей отображения инфологической модели в СУБД-ориентированные модели.
- Окончательный выбор СУБД.
Формирование информационного фонда.
- Определение источников получения информации.
- Определение характера возможной информации, характеристик информационных массивов (объем, частота, характер использования).
Построение концептуальной модели[19].
- Сопоставление инфологической модели с составом информационного фонда.
- Отображение инфологической модели в СУБД ориентированную.
- Описание концептуальной модели (построение концептуальной схемы БД средствами, предлагаемыми СУБД).
Построение внешних моделей.
- Разработка СУБД-ориентированных внешних моделей (в соответствии с результатами этапов 2 и 5).
- Отображение концептуальной модели во внешние модели.
- Описание внешних моделей (построение внешних схем БД средствами, предлагаемыми СУБД) [12].
Удобным и наглядным представлением процесса проектирования баз данных могут служить модели данных полученные в результате разработки структуры БД.
Таким образом, можно выделить следующие уровни перехода к конкретной реализации БД [10]:
- Предметная область
- Модель предметной области
- Инфологическая модель
- Концептуальная модель
- Внутренняя модель (физический уровень)
ER-диаграмма базы данных разработанной информационной системы приведена на рисунке 14.
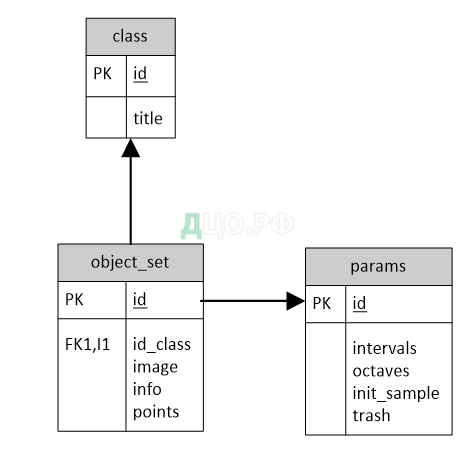
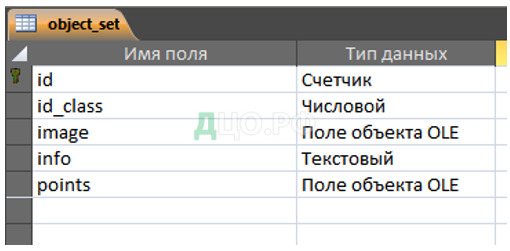
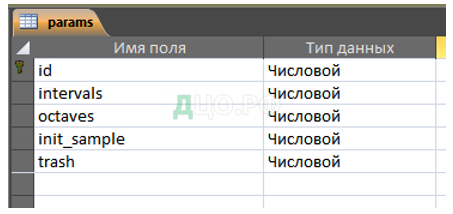
В таблице Class хранятся данные по описанию классов объектов, в таблице Object_set — данные по наборам элементов, в таблице params – параметры распознавания.
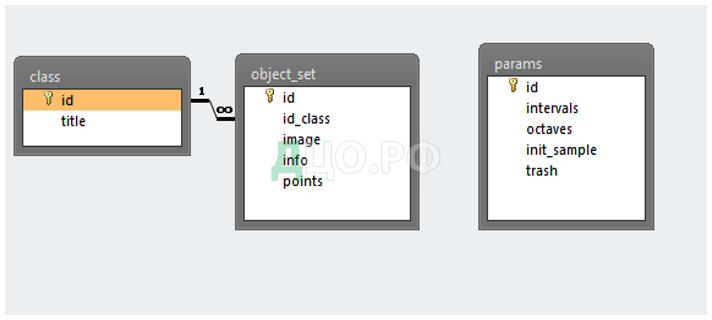
Далее была сформирована физическая модель базы данных в выбранной СУБД (рисунок 15)
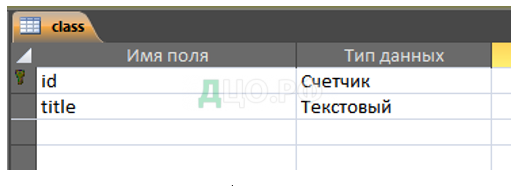
Ниже, на рисунках, представлена характеристика таблиц базы данных (рисунки 16-18).
или напишите нам прямо сейчас:
⚠️ Пожалуйста, пишите в MAX или заполните форму выше.
В России Telegram и WhatsApp блокируют - сообщения могут не дойти.