2. Моделирование основных бизнес-процессов проекта создания электронного предприятия
2.1 Моделирование бизнес-процессов проекта создания информационной системы электронного предприятия
Сущность подхода к разработке ИС заключается в ее декомпозиции (разбиении) на автоматизируемые функции: система разбивается на функциональные подсистемы, которые в свою очередь делятся на подфункции, подразделяемые на задачи и так далее. [14] Этапы декомпозиции происходят конечного результата. Одновременно с этим автоматизируемая система придерживается целостного представления, при котором все содержащие части скоррелированны. При создании системы «снизу-вверх» от определенных задач ко всей системе целостность теряется, появляются проблемы при информационной стыковке некоторых компонентов.
В структурном анализе применяются в большинстве случаев две группы средств, которые демонстрируют функции, осуществляемые системой и связь между данными. Самые известные виды моделей (диаграмм):
- SADT (Structured Analysis and Design Technique) модели и соответствующие функциональные диаграммы;
- DFD (Data Flow Diagrams) диаграммы потоков данных;
- ERD (Entity-Relationship Diagrams) диаграммы «сущность-связь». [2]
На каждом этапе проектирования информационной системы модели расширяются, уточняются и дополняются диаграммами, отражающими структуру программного обеспечения: архитектуру ПО, структурные схемы программ и диаграммы экранных форм. [2]
Вышеперечисленные модели в комплексе создают цельное описание информационной системы в независимости от того, является ли она действующей или создаваемой. [27]
Методология функционального моделирования SADT
Методология SADT разработана Дугласом Россом. Исходя из этой методологи, была разработана методология IDEF0 (Icam DEFinition).
Методология SADT является комплексом методов, правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области. Функциональная модель SADT отображает функциональную структуру объекта, т.е. производимые им действия и связи между этими действиями. [11] Элементы данной методологии базируются на следующих концепциях:
- графическое представление блочного моделирования. Графика блоков и дуг SADT-диаграммы представляет функцию в виде блока, а интерфейсы входа/выхода отображаются дугами, соответственно входящими в блок и выходящими из него. Взаимодействие блоков друг с другом описываются посредством интерфейсных дуг, выражающих «ограничения», которые в свою очередь определяют, когда и каким образом функции выполняются и управляются;
- строгость и точность. Выполнение правил SADT требует достаточной строгости и точности, не накладывая в то же время чрезмерных ограничений на действия аналитика. Правила SADT включают:
- ограничение количества блоков на каждом уровне декомпозиции (правило 3-6 блоков);
- связность диаграмм (номера блоков);
- уникальность меток и наименований (отсутствие повторяющихся имен);
- синтаксические правила для графики (блоков и дуг);
- разделение входов и управлений (правило определения роли данных).
- отделение организации от функции, т.е. исключение влияния организационной структуры на функциональную модель. [13]
Обычно эту методологию используют для:
- Моделирования систем;
- Формулировки требований и функций к системе;
- Создания системы, которая будет удовлетворять всем требованиям и функциям. [23]
Состав функциональной модели
После того как была использована методология SADT начинается создание диаграммы, эта диаграмма будет состоять из фрагментов текстов и глоссария, у них будут ссылки друг на друга. Диаграммы — это важные части модели, все функции ИС и интерфейсы на них представлены как блоки и дуги. С левой стороны находится информация, которая в дальнейшем будет подвергаться обработке, а с правой отображается результат выхода. Сверху показана управляющая информация, а снизу механизм, который и будет осуществлять операцию (рисунок 2.1.1). [27]
Отличительная черта методологии SADT — это поэтапное введение все больших уровней детализации по мере того, как создаются диаграммы, изображающие модель.
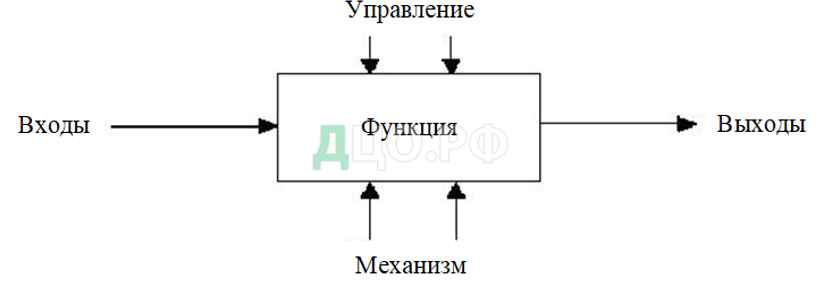
Рисунок 2.1.1 Функциональный блок и интерфейсные дуги [27]
Диаграммы потоков данных (Data Flow Diagrams — DFD) – это иерархия функциональных процессов, которая связанна с потоками данных. [2] Данная диаграмма демонстрирует, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами.
При построении DFD обычно используются две разные нотации, которые соответствуют методам Йордона-ДеМарко и Гейна-Сэрсона. Эти нотации несущественно различаются друг от друга графическим изображением символов (В последующих примерах используется нотация Гейна-Сэрсона).
Основными компонентами диаграмм потоков данных являются:
- внешние сущности;
- системы и подсистемы;
- процессы;
- накопители данных;
- потоки данных.
Для того чтобы представит внешнюю сущность берется материальный объект или физическое лицо, они будут являться источником или приемником информации. Обычно внешняя сущность изображается в виде квадрата, он находится над диаграммой и отбрасывает на нее тем, таким образом, внешняя сущность выделяется среди других обозначений. (Рисунок 2.1.2)
Рисунок 2.1.2 Графическое изображение внешней сущности
На контекстной диаграмме отображают строящуюся модель сложной системы и представляют это в виде единого целого или разбивают на ряд подсистем. [15]
Пример такой подсистемы (или системы) на контекстной диаграмме изображен на рисунке 2.1.3
Рисунок 2.1.3 Подсистема по работе с клиентами
Чтобы можно было идентифицировать подсистему для этого нужно дать ей номер. В поле имени нужно указать наименование подсистемы, которое будет в виде предложения с подлежащим и соответствующими определениями и дополнениями. [24]
Преобразование входных потоков данных в выходные, которое происходит в соответствии с заданным алгоритмом, называется процессом. [20]
Процесс на диаграмме потоков данных изображается на рисунке 2.1.4
Рисунок 2.1.4 Графическое изображение процесса
Для того чтобы идентифицировать процесс ему дается номер. В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым идут существительные в винительном падеже. [21]
Какое подразделение организации, какая программа или аппаратное устройство выполняет данный процесс, отображается в поле физической реализации.
Накопитель данных — это абстрактное устройство для хранения информации, любую информацию можно всегда поместить в накопитель, а после в любой момент извлечь, причем способы помещения и извлечения могут быть любыми. Накопитель данных на диаграмме потоков данных изображается, как показано на рисунке 2.1.5
Рисунок 2.1.5 Графическое изображение накопителя данных
Буквой «D» и произвольным числом обозначается накопитель данных. Имя накопителя подбирается из соображения наибольшей информативности для проектировщика. [26]
Образец будущей базы данных в общем случае — это накопитель данных, все описания, которые находятся в нем, должны соответствовать модели данных.
Определяет информацию поток данных, который передается через некоторое соединение от источника к приемнику. Данные могут передаваться:
- по кабелю между двумя устройствами;
- пересылаться по почте письмами;
- магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д. [3]
На диаграмме поток данных изображается линией, которая заканчивается стрелкой и показывает направление потока (Рисунок 2.1.6). Любой поток данных носит имя, которое отображает его содержание.
Рисунок 2.1.6 Поток данных
Основная цель, которая преследуется когда строиться иерархия DFD – это сделать описание системы ясным и понятным на любом уровне детализации, а также разбить его на части с точно сформулированными отношениями между ними. Чтобы достичь этого, нужно использовать следующие рекомендации:
- Отображать на каждой диаграмме от 3 до 6-7 процессов (аналогично SADT). Для этого верхняя граница должна соответствовать человеческим возможностям одновременного восприятия и понимания структуры сложной системы с большим количеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, которая содержит в себе всего один или два процесса.
- Не загромождать диаграммы незначительными на данном уровне деталями.
- Декомпозицию потоков данных нужно выполнять параллельно с декомпозицией процессов. Эти две работы должны осуществляться одновременно.
- Выбирать ясные, отражающие суть дела имена процессов и потоков, при этом стараться не использовать аббревиатуры. [6]
Первое действие, которое нужно сделать, начиная строить иерархию DFD – это построение контекстных диаграмм. Чтобы построить контекстную DFD с начала нужно проанализировать внешние события (внешние сущности), оказывающие влияние на функционирование системы. Потом определить какое количество потоков на контекстной диаграмме должно быть, желательно их количество должно быть небольшим, ведь каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы.
Детализация при помощи DFD выполняется для всех подсистем, которые находятся на контекстных диаграммах. Реализовать такое можно путем построения диаграммы для каждого события. Все события представляются в виде процесса с соответствующими входными и выходными потоками, накопителями данных, внешними сущностями и ссылки на другие процессы для описания связей между этим процессом и его окружением. После чего все построенные диаграммы сводятся в одну диаграмму нулевого уровня. [19]
Конечная вершина иерархии DFD – это спецификация. Исходя из следующих критериев, аналитик может принять решение об окончании детализации процесса и использовании спецификации:
- наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока);
- возможности описания преобразования данных процессов в виде последовательного алгоритма;
- выполнения процессом единственной логической функции преобразования входной информации в выходную;
- возможности описания логики процесса при помощи спецификации небольшого объема (не более 20-30 строк). [25]
2.2 Формирование бизнес-процессов создания электронного книжного магазина
Взаимодействие системы с окружающей средой описывается в терминах входа (на рисунке 2.2.1 это “Запрос покупателя на товар”), выхода (результат процесса — “Товар доставлен”, “Отказ покупки товара”), управления (“Закон о защите прав потребителя”) и механизмов (“Покупатель”, “Сотрудники книжного магазина” – это ресурсы, необходимые для процесса деятельность книжного магазина).
“Покупатели” – те, для кого интернет-магазин работает. Они платят магазину деньги в качестве платы за товар. Получение прибыли – цель коммерческой деятельности. Значит, чтобы добиться этой цели магазин должен продать товар покупателям.
«Закон о защите прав потребителя» – это нормативный документ, которым управляется процесс деятельность книжного магазина, согласно законодательству конкретной страны. [26]
В оказании услуг по продаже принимают участие «Сотрудники» книжного магазина.
Рисунок 2.2.1 Контекстная диаграмма IDEF0. «Деятельность книжного интернет-магазина».
Model Name: Книжный магазин
Definition: Модель описывает деятельность книжного магазина, а именно следующие предоставляемые им услуги:
- продажа товара;
- его доставка.
После описания контекстной диаграммы проводится функциональная декомпозиция — система разбивается на подсистемы и каждая подсистема описывается отдельно (диаграммы декомпозиции). Затем каждая подсистема разбивается на более мелкие и так далее до достижения нужной степени подробности. В результате такого разбиения, каждый фрагмент системы изображается на отдельной диаграмме декомпозиции (Рисунок 2.2.2).
Рисунок 2.2.2 «Диаграмма декомпозиции IDEF0. Деятельность книжного интернет-магазина»
Весь процесс “ Деятельности книжного магазина” разбивается на:
1) “Проверка БД[1] на наличие товара” иллюстрирует Проверку БД на наличия товара по запросу покупателя.
2) “Оформление заказа” представляет собой процесс сборки нужных товаров для заказа. Его бронирование. И формирование договора купли продажи
3) “Оплата товара и его отдача” – это Оплата товара указанного в договоре купли продажи. И его последующая доставка.
Рисунок 2.2.3 Диаграмма декомпозиции IDEF0. «Оформление заказа»
Рисунок 2.2.4 Диаграмма декомпозиции IDEF0. «Оплата товара и его отдача»
Если в процессе моделирования нужно осветить специфические стороны технологии предприятия, BPwin позволяет переключиться на любой ветви модели на нотацию IDEF3 или DFD и создать смешанную модель.
Диаграммы потоков данных (DFD) используются для описания документооборота и обработки информации. Нотация DFD включает такие понятия, как «внешняя ссылка» и «хранилище данных», что делает ее более удобной (по сравнению с IDEF0) для моделирования документооборота. [12]
На рисунке 2.2.5 представлены:
1) “Договор купли продажи” и ”Товар оплачен” – это внешние ссылки, источник данных извне модели.
2) “БД документов” и ”Счет фирмы” – хранилища данных.
Рисунок 2.2.5 Диаграммы декомпозиции в нотации DFD. «Оплата товара»
В отличие от стрелок IDEF0, которые представляют собой жесткие взаимосвязи, стрелки DFD показывают, как объекты (включая данные) двигаются от одной работы к другой. Например, “Информация для формирования счета”, поступает из договора купли продажи и инициирует процедуру “Счет”. В ней происходит занесение документа в БД документов, отмечается будущее убытие товара. Это впоследствии переходит к подтверждению на оплату товара. Здесь клиент может решить: оплачивать ему товар или нет. Если он не оплачивает товар — все операции завершаются. Если же оплачивает, то происходит проводка документов. Зачисление средств на счет. Впоследствии переходит к внешней сущности, которая завершает эту диаграмму и передает управление диаграммам верхнего уровня.
На Диаграмме декомпозиции в нотации IDEF3. Идентификация товаров и покупателя (на рисунке 2.2.6) иллюстрируется ”Идентификация товаров и покупателя”. Идентификация товаров учитывается в нашей базе.
После формирования покупательской корзины, запускаются все последующие за перекрестком (AND) процессы:
- “Идентификация покупателя”;
- “ Идентификация товара ”.
После сбора этих данных через перекресток (XOR) идентификация товаров подходит к завершению на внешнюю стрелку. Идентификация завершена.
Рисунок 2.2.6 Диаграммы декомпозиции в нотации DFD. «Оплата товара»
Старшая (Precedence) линия — сплошная линия (®), связывающая единица работ. Она была использована для того, чтобы показать, что работа-источник должна закончиться прежде, чем работа-цель начнется. [6]
Диаграмма дерева узлов показывает иерархию работ в модели и позволяет рассмотреть всю модель целиком, но не показывает взаимосвязи между работами.
На рисунке 2.2.7 представлено итоговое расположение работ в дереве узлов:
- диаграмма “деятельность книжного магазина” – 1-ый уровень дерева узлов (top level activity);
- диаграммы “Проверка БД на наличие товара”, “оформление заказа” и “оплата товара и его отдача” – 2-ой уровень дерева узлов;
- диаграммы “Идентификация покупателя и товаров”, “Бронирование заказа”, “Формирование договора купли продажи”, “Оплата товара”, “Сборка и упаковка заказа”, “Доставка товара” – 3-ий уровень.
Рисунок 2.2.7 Диаграмма дерева узлов.