6.2. Ускоренный алгоритм Берлекэмпа – Месси
Ускоренный алгоритм обосновывается следующим образом. На начальных итерациях алгоритм Берлекэмпа—Месси в частотной области содержит умеренное число умножений порядка степени многочлена L (х). Но степень многочлена L (х) возрастает до существенной доли длины n, и таким образом, среднее число умножений на итерацию имеет порядок n. Преимущества ускоренного алгоритма связаны попросту с тем, что на ранних шагах несколько итераций в частотной области выполняются одновременно. После такого пакетного выполнения нескольких итераций полученный промежуточный результат используется для модификации синдрома путем ввода в него вычисленных в этом пакете многочленов L (х) и В (х). Следующий пакет итераций начинает выполнение алгоритма Берлекэмпа—Месси, сначала используя в качестве синдрома вычисленный модифицированный синдром и полагая в начальный момент L (х) равным 1.
В перестроенном виде алгоритм Берлекэмпа—Месси основывается на двух уравнениях:
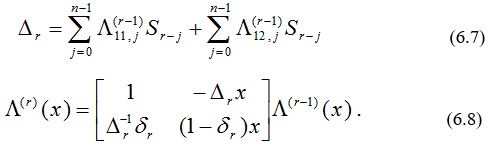
Теперь можно уменьшить число вычислений, группируя итерации в пакеты. Определим матрицу
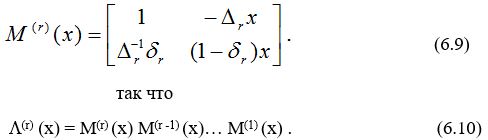
Это произведение должно вычисляться последовательно по одному члену, начиная справа, так как M(r) (x) нельзя вычислить до тех пор, пока не вычислена L(r -1) (x).
Определим следующие частичные произведения рассматриваемых матриц:
L(r) (x) = L(r , 0) (x) (6.11)
L(r) (x) = L(r , r’) (x) L(r’) (x). (6.12)
Определим вектор модифицированных синдромных многочленов S(r) (x):
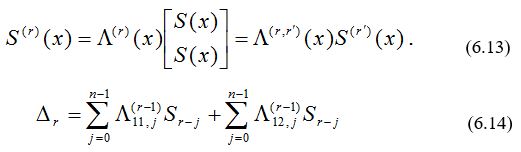
Невязка становится равной r – му члену свертки и может быть записана через многочлены :
D(x) = L11(r –1, r’) (x) [ L11( r’) (x)S(x) + L12( r’) (x)S(x) ] + L21(r –1, r’) (x) [ L21( r’) (x)S(x) + L22( r’) (x)S(x) ]. (6.15)
Стоящие в квадратных скобках многочлены являются компонентами вектора S(r’) (x) модифицированных синдромных многочленов. Следовательно, выражение для невязки можно переписать в виде
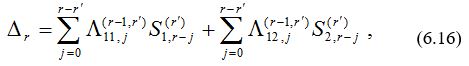
где S(r)1 , j и S(r)2 , j обозначают соответственно j-е коэффициенты многочленов в первой и второй компонентах вектора S(r) (х). Для ускорения алгоритма Берлекэмпа—Месси сформируем пакеты по t итераций в каждом. Если t делит 2t, то обращение к каждому из 2t/t пакетов одинаково. В противном случае последний пакет содержит меньше t итераций, но мы полагаем его таким же. Индекс r теперь пробегает значения
r = 1, 2,…, t, t+1,…, 2t, 2t+1,…, 3t, 3t+1,…
На r-й итерации k-го пакета модифицированный алгоритм Берлекэмпа—Месси вычисляет L(r , r’) (х) согласно равенству
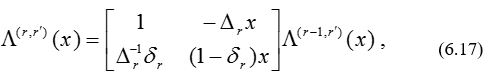
где r’ = kt , а Dr вычисляется по формуле
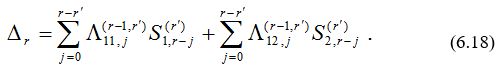
В конце k-го пакета, когда r равно (k + 1)t, матрица локаторов ошибок и вектор модифицированных синдромных многочленов даются соответственно равенствами
L(r) (x) = L(r, r’) (x) L(r’) (x) (6.19)
S(r) (x) = L(r, r’) (x) S(r’) (x) , (6.20)
где r’ = kt и r = (k + 1)t . Теперь ускоренный алгоритм готов начать (k + 1)–й пакет.
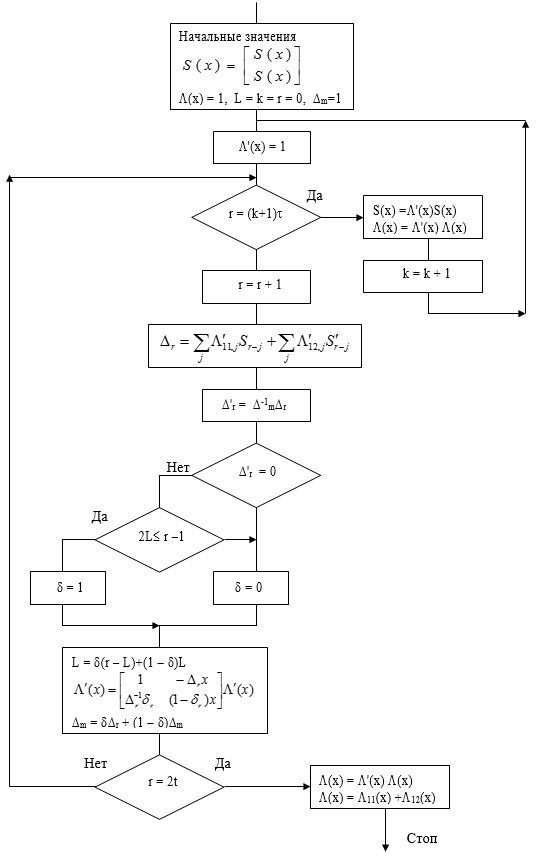
На рисунке 6.2 приведена блок-схема ускоренного алгоритма Берлекэмпа — Месси с некоторыми очевидными сокращениями. Если правая часть алгоритма выполняется так, как она выписана, то мы не получаем никакой экономии вычислений. Однако умножения многочленов в блоках эквивалентны сверткам, которые могут быть эффективно вычислены с помощью быстрого преобразования Фурье и теоремы о свертке.
ГЛАВА 7. ИСПРАВЛЕНИЕ СТИРАНИЙ И ОШИБОК
В дипломной работе используется каскадный код, внешним кодом которого является код Рида – Соломона (255, K, D) над полем GF (28), а внутренним – код Голея (24, 12, 8). В следствии чего три 8-битных символа внешнего кода составляют два 12-битных кодовых слова внутреннего кода. При декодировании внутреннего кода могут появиться стертые кодовые слова – это слова в которых произошло четыре ошибки, и значит они не могут быть декодированы. Стертые кодовые слова внутреннего кода заменяются нулями, обозначающими стирания. Следовательно во внешнем коде появляются два стертых 8-битных символа, заполненных нулями. В силу чего декодер внешнего кода должен исправить ошибки и восстановить стертые символы. Код с минимальным расстоянием d* позволяет декодировать любую конфигурацию, содержащую v ошибок r стираний, при условии, что
d* ³ 2v + t + r. (7.1)
Наибольшее v, удовлетворяющее этому неравенству, обозначим через tp.
Чтобы декодировать принятое слово с r стираниями, необходимо найти кодовое слово, которое в нестертых позициях отличается от принятого слова не более чем в tp символах. Поскольку по определению параметра tр такое слово единственно, разыскивается любое подходящее слово. Нам нужно только найти какое либо решение, так как мы знаем, что оно лишь одно.
Один из возможных способов декодирования состоит в угадывании стертых позиций с последующим применением любой процедуры исправления ошибок. Если процедура приводит к исправлению не более tp ошибок в нестертых позициях, то кодовое слово восстанавливается. Если необходимо исправлять слишком много ошибок, то делается новая попытка угадать стертые символы. При этом любая подходящая для данного кода процедура исправления ошибок может быть модифицирована в процедуру исправления ошибок и стираний. Практически она подходит в тех случаях, когда число комбинаций угадываемых стертых символов мало. В противном случае такая процедура проб и ошибок становится практически неприемлемой. В таких случаях восстановление стертых символов должно осуществляться некоторым регулярным способом, входящим в алгоритм декодирования.
Класс кодов БЧХ допускает многие сильные алгоритмы декодирования. Все они могут быть обобщены на случай декодирования ошибок и стираний. Для простоты будем полагать j0 = 1.
Пусть Vi, i = 0, …, n — 1, обозначают символы принятого вектора. Предположим, что стирания произошли в позициях i1, …, ip. Во всех этих позициях принятое слово содержит пробелы, которые мы сначала заполним нулями. Определим n-мерный вектор стираний, положив символы в стертых позициях равными fil , l = 1, …, r, а в остальных позициях равными нулю. Тогда
vi = ci + ei + fi , i =0, . . . , n — 1 . (7.2)
Пусть y — произвольный вектор, символы которого равны нулю в каждой позиции стирания и только в них. Тогда
yi vi = yi (ci + ei + fi ) = yi ci + yi ei (7.3)
Определим модифицированное принятое слово равенством v’i = yi vi, модифицированный вектор ошибок равенством e’i = yi ei и модифицированное кодовое слово равенством c’i = yi ci. (Модифицированный вектор ошибок содержит ошибки в тех же позициях, что и исходный вектор ошибок е.) Тогда последнее равенство приводится к виду
v’i = c’i + e’i . (7.4)
Теперь задача состоит в декодировании вектора v’ и сводится к задаче вычисления вектора е’, которую можно решить при достаточном числе компонент синдрома.
Следующий шаг построения алгоритма состоит в выборе вектора Y. Пусть Ul = ail для l = 1, …, r обозначают локаторы стираний. Определим многочлен локаторов стираний равенством
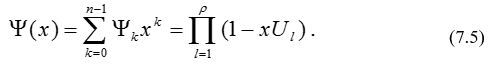
Этот многочлен специально определен так, чтобы компоненты yi обратного преобразования вектора Y были равны нулю, как только fi ¹ 0. Следовательно, yi fi = 0. В частотной области это дает
V’ = (Y * С) + Е’. (7.6)
Но вектор Y отличен от нуля только на блоке длины r + 1, а по построению кода БЧХ вектор С имеет нулевые компоненты в блоке длины 2t. Следовательно, свертка Y * С равна нулю в блоке длины 2t — r. Полагая S’j = V’j, определим на этом блоке модифицированный синдром. Тогда
S’j = (Y*V)j + E’j , (7.7)
что задает достаточное число компонент синдрома для исправления модифицированного вектора ошибок.
Итак, точно так же, как в случае наличия только ошибок (при условии, что их не более (2t — r)/2 ), по этим 2t — r известным компонентам вектора Е’ можно найти многочлен локаторов ошибок L (х). Так как многочлен локаторов ошибок известен, можно скомбинировать его с многочленом локаторов стираний и дальнейшее декодирование проводить так же, как и в случае наличия только ошибок. Чтобы проделать это, определим сначала многочлен локаторов ошибок и стираний:
L’ (х) = Y(х)L(x) . (7.8)
Обратное преобразование Фурье вектора L’ содержит нуль в позиции каждой ошибки и каждого стирания. Таким образом, li = 0, если еi ¹ 0 или fi ¹ 0. Следовательно, li (ei + fi) = 0,
L’ * (Е + F) = 0, (7.9)
и многочлен L’ отличен от нуля в блоке длины, не превышающей v + r + 1. Следовательно, используя известные компоненты вектора L’ и 2t известных компонент вектора Е + F, можно воспользоваться этим содержащим свертку уравнением для того, чтобы рекуррентно продолжить вектор Е + F до всех n компонент. Затем вычисляются
Ci = Vi – (Ei + Fi). (7.10)
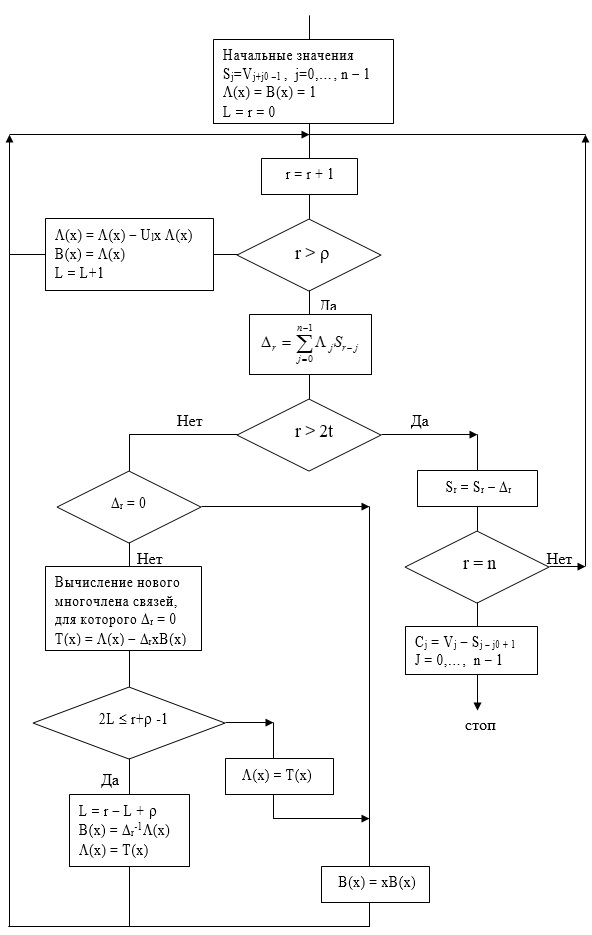
Вычисление многочлена локаторов ошибок по модифицированному значению синдрома можно выполнить с помощью алгоритма Берлекэмпа—Месси. Можно улучшить алгоритм Берлекэмпа – Месси, если скомбинировать несколько шагов. Идея алгоритма состоит в рекуррентной процедуре вычисления многочлена L(x) за 2t итераций, начиная с оценок L(0) (x) = 1 и B(0) (х) = 1.
В случае наличия стираний в уравнении для невязки Dr компоненты синдрома заменяются компонентами модифицированного синдрома:
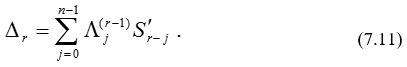
Многочлен локаторов ошибок вычисляется с помощью n итераций при начальных условиях L(0) (x) = 1 и B(0) (х) = 1.
Заменим начальные условия на L(0) (x) = B(0) (x) = Y (x). Тогда
L(r) (x) Y (x) = L(r -1) (x) Y (x) – Dr B(r -1) (x) Y (x) , (7.12)
B(r) (x) Y (x) = (1 – dr)x B(r -1) (x) Y (x) + dr Dr-1 L(r -1) (x) Y (x) . (7.13)
Если мы временно определим L’(r) (x) = L(r) (x) Y (x) и будем вычислять невязку Dr по формуле
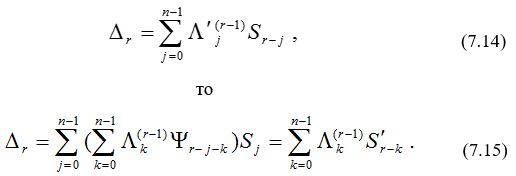
Итак, если в качестве начальной точки в алгоритме Берлекэмпа – Месси вместо 1 выбрать многочлен Y(х), то модифицированный синдром вычисляется неявно и нет необходимости вводить его в явном виде. Отбросим теперь обозначение L'(х), заменив его на L (х) и назвав многочленом локаторов ошибок и стираний. При начальных условиях, даваемых многочленом Y (х), алгоритм Берлекэмпа — Месси рекуррентно порождает многочлен локаторов ошибок и стираний в соответствии с уравнениями
L(r) (x) = L(r -1) (x) – Dr x B(r -1) (x) , (7.16)
B(r) (x) = (1 – dr)x B(r -1) (x) + dr Dr-1 L(r -1) (x) , (7.17)
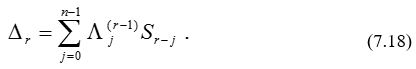
ГЛАВА 8. СТРУКТУРА CRC – КОДА
В дипломной работе используется алгоритм циклических избыточных кодов — Cyclic Redundancy Codes (в дальнейшем СRС). Этот алгоритм представляет собой высокоэффективное средство обнаружения ошибок. Благодаря вычислению циклической контрольной суммы мы можем определить искажения данных, так как изменение данных приводит к изменению циклической контрольной суммы. Основным свойством алгоритма является то, что циклическая контрольная сумма изменится как при искажении одного так и более битов информационной последовательности.
При получении циклической контрольной суммы исходные данные, представленные в виде двоичной последовательности : a0, a1, a2,…, an-2, an-1 , удобно рассматривать, представляя комбинацию двоичного кода в виде характеристического полинома от фиктивной переменной x, а именно :
K(x) = an-1x n-1 + an-2x n-2 +…+ a2x 2 + a1x + a0 ,
где ai – цифры двоичного кода исходных данных.
Так например двоичную последовательность 11100110 можно представить в виде полинома :
K(x) = 1x 7 + 1x 6 +1x 5 + 0x 4 + 0x 3 + 1x 2 + 1x 1 + 0x 0 = x 7 + x 6 +x 5 + x 2 + x .
Представление двоичной последовательности в виде характеристического полинома позволяет свести действия для получения СRС к операциям над многочленами. При этом сложение двоичных многочленов сводится к сложению по модулю два коэффициентов при одинаковых степенях переменной x ; умножение производится по обычному правилу перемножения степенных функций, однако полученные при этом коэффициенты при одинаковых степенях переменной x складываются по модулю два ; деление осуществляется по правилам деления степенных функций, при этом операции вычитания заменяются операциями суммирования по модулю два. [1]
Процедура получения CRC – кода состоит в следующем :
Исходная последовательность, представленная в виде характеристического многочлена K(x), умножается на одночлен x n , а затем делится на образующий полином G(x) степени n. В результате умножения K(x) на x n степень каждого одночлена, входящего в K(x), повысится на n. При делении произведения K(x) · x n на образующий полином G(x) получится частное — Q(x) такой же степени, как и K(x), и остаток — R(x), степень которого не больше n-1. Результат умножения и деления можно представить в следующем виде:
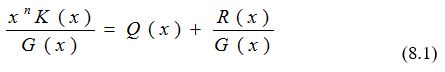
Умножая обе части равенства на G(x) и проведя некоторые перестановки, получим:
N(x) = xn K(x) + R(x) (8.2)
В правой части формулы знак минус перед R(x) заменен знаком плюс, так как вычитание по модулю два сводится к сложению.
Таким образом, последовательность бит, представляемая собой коэффициенты полинома R(x), добавляемая к информационной последовательности, является циклической контрольной суммой, а итоговой кодовой последовательностью является коэффициенты полинома N(x).
После передачи сообщения по каналу на передаваемую последовательность могут накладываться ошибки, в следствии чего принятая комбинация примет вид :
M(x) = N(x) + E(x), (8.3)
где E(x) – вектор ошибки.
Определить наличие ошибок в принятой последовательности можно с помощью остатка от деления полинома M(x) на образующий полином G(x). Если E(x) = 0 (ошибок в сообщении нет), остаток от деления равняется нулю, то есть (N(x) + E(x)) mod G(x) = 0 , иначе остаток от деления не равен нулю, что свидетельствует о наличии ошибок в принятой последовательности.
Существует вероятность того что обнаружение ошибок не произойдет при наличии ошибок в принятой последовательности. Это произойдет если вектор ошибок равен порождающему полиному, или является его произведением, то есть E(x) = G(x)A(x).
Так например нужно закодировать двоичную последовательность 11100110 :
K(x) = x 7 + x 6 +x 5 + x 2 + x
Порождающий полином выберем G(x) = x 4 + x 3 + 1
K(x) · x 4 = x 11 + x 10 +x 9 + x 6 + x 5
R(x) = (K(x) · x 4 ) mod G(x) = x 2 + x
N(x) = K(x) · x 4 + R(x) = x 11 + x 10 +x 9 + x 6 + x 5 + x 2 + x
Теперь допустим произошла ошибка, которой соответствует полином E(x) = x 6 + x 5 + x 2 = G(x) · x 2 в следствии чего
N(x) + E(x) = x 11 + x 10 +x 9 + x и (N(x) + E(x)) mod G(x) = 0 .
Остаток от деления равен нулю хотя произошли ошибки. Поэтому для понижения вероятности этого события в качестве порождающего полинома выбирают неприводимый полином, то есть который нельзя разложить на множители. Так же можно понизить вероятность ошибки используя порождающий полином большей степени.
Для решения вышеуказанной задачи применяется множество алгоритмов расчёта CRC. Самыми распространёнными, на данный момент, являются алгоритмы CRC-16, CRC-24, CRC-32. Расчеты показывают, что чем выше степень порождающего полинома, тем меньше вероятность ошибки. Например, используя алгоритм CRC-32, вероятность ошибки составит 1/232. Для уменьшения вероятности ошибки можно увеличить добавляемый остаток в два раза путем применения CRC – кода последовательно второй раз.
В дипломной работе используется алгоритм CRC-32, что означает применение 32 битного порождающего полинома :
x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1
Такой полином обеспечивает вероятность ошибки 2-32 ≈ 2,3 · 10-10, но в силу того что CRC – код применяется последовательно два раза, остаток становится равным 64 бита, следовательно вероятность ошибки составит 2-64 ≈ 5,421 · 10-20.
ГЛАВА 9. ПРЕОБРАЗОВАНИЯ СООБЩЕНИЯ
Основной целью данной систем передачи информации является достоверность принятого сообщения, поэтому все действия направлены на то, чтобы принятое сообщение было декодировано точно, то есть совпало с переданным сообщением. В связи с этим передаваемая последовательность кодируется каскадным кодом, внешний код которого является кодом Рида-Соломона с характеристиками (255, K, D), а внутренний – модифицированным кодом Голея с характеристиками (24, 12, 8). Так же к исходному сообщению будет добавляться контрольная сумма CRC, которая будет использована для проверки кодовой последовательности на заключительном этапе, и в случае ее не совпадения будет производиться перебор стертых кодовых слов внутреннего кода до тех пор пока контрольная сумма не совпадет.
В процессе передачи сообщения от источника к потребителю исходное сообщение трансформируется в различные формы, удобные для той или иной операции. Распишем последовательность преобразований, происходящих с исходным сообщением в процессе операций кодирования и декодирования.
- Формирование двоичной последовательности исходного сообщения. Оно будет представлено в виде последовательности из N бит :
a0, a1, a2, …, aN-1 .
- Вводим первую избыточность данных в виде m бит циклической контрольной суммы CRC, которая используется для проверки кодовой последовательности на заключительном этапе. Таким образом исходное сообщение будет представлено в виде последовательности из N+m бит :
a0, a1, a2, …, aN-1, aN, aN+1, aN+2, …, aN+ m-1 .
- Поскольку кодирование будет производиться по принципу каскадного кодирования, внешним кодом которого является код Рида–Соломона, определенный над полем GF(28), то необходимо разбить исходную ..последовательность на блоки по 8 бит. .
a0, a1,…, a7, a8, a9,…, a15, …… , aN+ m-9,aN+ m-8,…, aN+ m-1
То есть получается новая последовательность :
a0, a1, … , a(N+ m) / 8–1 ,
каждый символ которой является элементом поля GF(28). Преобразованная последовательность будет использоваться как исходная для внешнего кода.
- Далее данная последовательность кодируется кодом Рида-Соломона с характеристиками (255, K, D) , где
K = (N + m)/8
D = 255 – K + 1
Таким образом вводится избыточность, и последовательность представляется в виде 255 элементов поля GF(28), каждый из которых по 8 бит :
b0, b1, … , b254 .
- В качестве внутреннего кода каскадного кода используется код Голея с характеристиками (24, 12, 8). И так как количество информационных символов данного кода равняется 12, то последовательность из 255 элементов по 8 бит нужно разбить на символы над полем GF(212), то есть на 170 элементов по 12 бит.
b0, b11 , b12, b2, b3, b41, b42, b5, …
⇓ ⇓ ⇓ ⇓
g0 g1 g2 g3 … ,
где bi1 — первые 4 бита элемента bi , а bi2 – вторые 4 бита bi .
Преобразованная последовательность будет использоваться как исходная для внутреннего кода.
- Полученная последовательность поэлементно кодируется кодом Голея с характеристиками (24, 12, 8). В итоге последовательность представляется в виде 170 элементов, каждый из которых содержит по 24 бита :
d0, d1, … , d169 .
- Перед отправкой преобразованного сообщения на модулятор необходимо произвести еще одно преобразование последовательности, а именно разбиение закодированных блоков на символы алфавита {Ck}, согласованного с модемом :
c0, c1, … , c170*24 / i -1 ,
где i – количество бит в одном символе алфавита {Ck}, определяется характеристиками модема.
- Далее закодированная последовательность подается на модем, где преобразуется в последовательность сигналов, которые с передатчика отправляется в эфир.
Процесс восстановления сообщения на приемной стороне системы передачи информации будет происходить в обратном порядке.
- Принятый сигнал с помощью модема преобразуется в последовательность кодовых символов :
c0, c1, … , c170*24 / i -1
- Преобразование символов алфавита {Ck}, согласованного с модемом, в последовательность для внутреннего декодера (170´24 бита) :
d0, d1, … , d169
- Декодирование кода Голея. Последовательность примет вид 170 блоков по 12 бит :
g0, g1 , … , g169
- Преобразование последовательности для внешнего декодера (255´8 бит) :
b0, b1, … , b254 .
- Декодирование кода Рида — Соломона. Последовательность примет вид 170 блоков по 8 бит :
a0, a1, … , a169 .
- Далее следует вычисление и проверка циклической контрольной суммы CRC. Если проверка дала положительный результат, то полученное сообщение совпадает с переданным и посылается получателю.
ГЛАВА 10. ПРОГРАММНАЯ РЕАЛИЗАЦИЯ РАЗРАБОТАННОЙ КОДОВОЙ КОНСТРУКЦИИ
Программная реализация разработанной кодовой конструкции осуществлена в среде Microsoft Visual C++ 6.0 . Эта среда разработки программного обеспечения дает такие качества как универсальность применения, логическую стойкость и удобочитаемость исходного кода программы.
Минимальные требования, предъявляемые к компьютеру:
- процессор Pentium II 450 MHz;
- объем оперативной памяти не менее 64Мб (желательно 128 и более)
- монитор SVGA;
- дисковод CD-ROM – для установки приложений Microsoft Visual C++;
- клавиатура;
- мышь;
- объем свободного дискового пространства 10 Мбайт
На компьютере должна быть установлена одна из операционных систем Windows 98, Windows 2000, Windows ME, Windows NT или Windows ХР.
ГЛАВА 11. РЕКОМЕНДАЦИИ ПО ИСПОЛЬЗОВАНИЮ
Разработанная в дипломной работе система передачи информации предназначена для систем передачи информации без обратной связи, где требуется высокая достоверность принятого сообщения. Так как основным критерием является достоверность принятого сообщения, в следствии чего возросла сложность кодовой конструкции и увеличился объем вычислений, то в других системах данную конструкцию применять не рекомендуется. В системах с обратной связью сложность кодовой конструкции и объем вычислений можно сделать гораздо меньше.